

Improving search relevance is an ongoing process that requires continuous attention. It requires balancing the question a user asks and what they actually want. If someone searches for “apple,” is that person looking for a snack, a new phone, or a stock price?
For most teams, improving search relevance means navigating three massive hurdles:
- The intent gap: Decoding ambiguous queries and balancing precision (returning only relevant results) with recall (returning sufficient results).
- The data struggle: Dealing with “noisy” metadata or niche datasets in which information is sparse or incomplete.
- The scale problem: What works in a small test environment often fails under the chaotic, high-volume reality of production traffic.
TL;DR
- AI-powered agent that automates search relevance tuning via natural language in OpenSearch Dashboards
- Three agents analyze query patterns, generate tuning strategies, and validate improvements automatically
- Reduces relevance diagnosis from days to hours — no deep search expertise required
- Human-in-the-loop: you steer, the agent executes
- Available now in OpenSearch 3.6 (experimental) via the Agent Server repo
The problem with manual tuning
Traditionally, tuning relevance is a marathon. It often takes months of manual tweaking by search experts to find the “perfect” settings. But in the modern enterprise, data doesn’t stay still. Seasonal trends and evolving product catalogs expand the search space faster than humans can adapt.
This leaves organizations stuck in a cycle of reactive tuning, struggling to maintain high-quality results across millions of unique queries.
Automate search quality
To break this cycle, the OpenSearch Project introduces a faster, smarter way to optimize your search experience. The OpenSearch Relevance Agent is designed to automate complex tuning tasks, allowing you to move from intuition-based tuning to data-driven precision in a fraction of the time. OpenSearch Relevance Agent continuously analyzes user behavior signals and query patterns, generates data-driven hypotheses, and validates improvements through rigorous offline evaluation.
Through a conversational interface in OpenSearch Dashboards, you interactively identify relevance issues, receive guided tuning recommendations, and execute complex workflows using natural language. This makes advanced relevance optimization accessible to all teams.
OpenSearch Relevance Agent delivers immediate value in any environment. While it’s designed to use User Behavior Insights (UBI) data when available for deeper optimization, UBI is not required to begin transforming your relevance workflow. Future releases will add support for additional data sources.
Using the full capabilities of the Search Relevance Workbench, OpenSearch Relevance Agent enables end-to-end experimentation, from creating query sets and judgment lists, to running controlled tests and quantifying impact using standard relevance metrics. The system orchestrates a systematic, automated tuning workflow that abstracts the complexity of relevance engineering. In OpenSearch 3.6, it delivers immediate impact through actionable query-DSL-level optimizations such as refining search fields, adjusting weights, and tuning boost functions.
OpenSearch Relevance Agent is one of the agents supported in OpenSearch Agent Server in version 3.6 as an experimental release. The OpenSearch Agent Server is a multi-agent orchestration platform that enables you to build specialized AI agents that work together within OpenSearch.
Empowering teams to deliver better search, faster
OpenSearch Relevance Agent provides several key benefits that transform the way you approach search optimization:
- Accelerated developer velocity: Reduce time-to-diagnose and fix relevance issues from days or weeks to hours. OpenSearch Relevance Agent automates root-cause analysis and tuning workflows, enabling rapid iteration and faster release cycles.
- Democratization of relevance engineering: Eliminate dependency on scarce search relevance experts. OpenSearch Relevance Agent empowers any developer or product team to confidently tune search quality through guided, agent-driven workflows—lowering the barrier to entry across the organization.
- Evidence-driven confidence: Replace intuition-based tuning with automated evaluation and validation loops. OpenSearch Relevance Agent continuously tests changes against real queries and datasets, ensuring that improvements are measurable, explainable, and without unintended regressions.
- Human-in-the-loop control: Maintain full oversight of the optimization process using a collaborative approach. While OpenSearch Relevance Agent automates complex tasks, you remain the ultimate decision-maker—steering the agent’s direction, providing critical domain-specific context, and refining recommendations to ensure that they align perfectly with unique business requirements and expert intuition.
How it works: A multi-agent system built for OpenSearch
OpenSearch Relevance Agent enables you to enter the conversation at any stage of the search improvement cycle, whether beginning with a diagnostic check or bringing specific hypotheses for immediate validation. Instead of a single bot trying to do everything, the Relevance Agent uses a multi-agent system—a specialized task force led by an Orchestrator that manages three experts in a three-agent workflow:
- User Behavior Analysis Agent identifies relevance gaps by analyzing UBI data (when available) or query patterns.
- Hypothesis Generator Agent interprets results in order to create data-driven tuning strategies.
- Evaluator Agent validates strategies by running automated tests against offline evaluation sets within the Search Relevance Workbench.
Technical architecture: Built for the OpenSearch platform
The OpenSearch Relevance Agent is not just a standalone tool; it integrates directly into your existing OpenSearch environment, as shown in the following diagram.
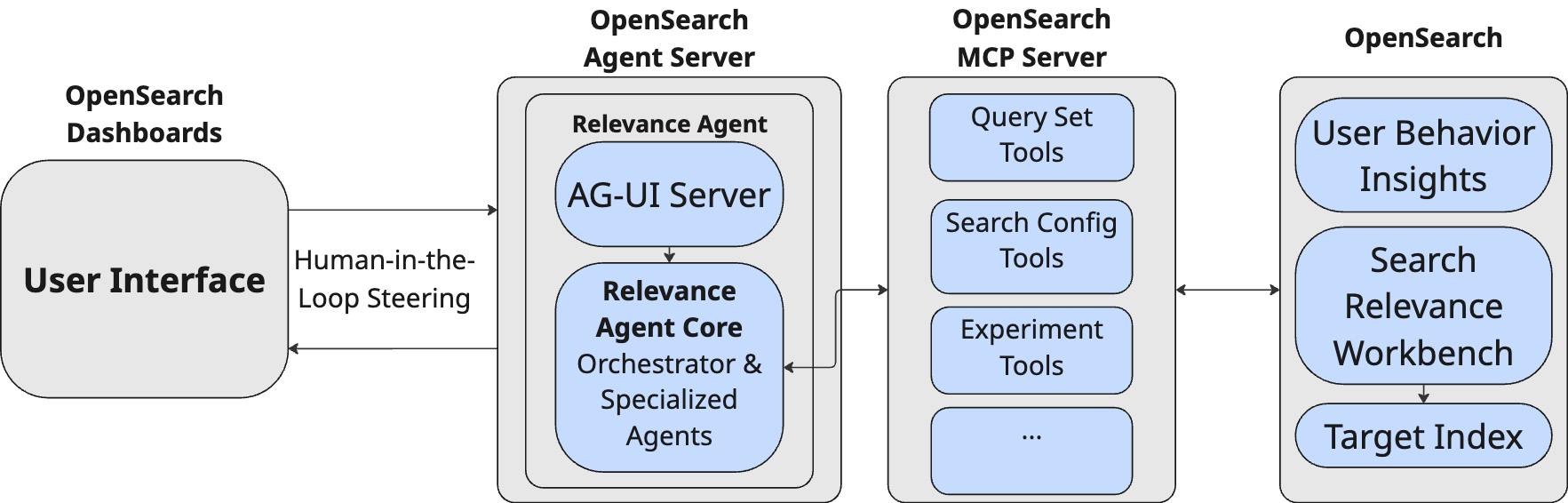
The OpenSearch Relevance Agent architecture comprises the following key components:
- Seamless integration: Built on the Strands SDK, the agent integrates directly with your OpenSearch Dashboards chat through the AG-UI standard.
- The MCP Server: All agents communicate with the search engine exclusively through the OpenSearch Model Context Protocol (MCP) server. This abstraction layer acts as a secure translator between the AI and your search engine, allowing OpenSearch Relevance Agent to use the full power of the Search Relevance Workbench through standardized tools.
- Facts over intuition: The system uses specialized tools within the agent environment to handle complex metric calculations. By offloading these computations from the large language model (LLM) to deterministic tools, OpenSearch Relevance Agent significantly reduces the risk of hallucinations or mathematical estimations, ensuring that every Key Performance Indicator (KPI) and relevance metric reported back to you is grounded in rigorous, error-free analysis.
Getting started with OpenSearch Relevance Agent
Follow these steps to configure OpenSearch Relevance Agent in minutes.
Prerequisites
For the quickstart script you need to have Java 21+, Node.js 20+, Python 3.12+, uv, yarn, jq, and curl installed. You also must have access to an LLM hosted on Amazon Bedrock (additional model providers will be supported in the future).
1. Clone the repository
First, clone the OpenSearch Agent Server repository and navigate into the project folder:
git clone https://github.com/opensearch-project/opensearch-agent-server.git
2. Configure environment variables
Create your local environment file from the provided template:
cp .env.example .env
Open the .env file in your preferred editor and add your Amazon Bedrock credentials and configuration:
AWS_ACCESS_KEY_ID=your_access_key AWS_SECRET_ACCESS_KEY=your_secret_key AWS_REGION=us-east-1 BEDROCK_INFERENCE_PROFILE_ARN=arn:aws:bedrock:...
Note: Ensure that your AWS IAM user has the necessary permissions for the Amazon Bedrock model invocation.
3. Launch the quickstart script
Run the automated setup script. This script downloads, configures, and launches all necessary components, including OpenSearch, OpenSearch Dashboards, and the OpenSearch Agent Server:
./scripts/quickstart.sh
This process typically takes a few minutes. If you see a “OpenSearch Dashboards did not load properly” error in your browser, wait another 2–3 minutes for the backend services to fully initialize.
4. Start tuning
Once the setup is complete, navigate to OpenSearch Dashboards at http://localhost:5601:
- OpenSearch Dashboards automatically opens a preconfigured Search Workspace.
- Select the “Ask AI” button in the upper-right corner to open the OpenSearch Relevance Agent interface.
- Try the prompt “What are “underperforming” queries of the past two years?”, as shown in the following video:
{% include youtube-player.html id=’N5BL_iaKpJQ’ %}
The agent immediately begins analyzing the sample UBI data indexed by the quickstart script and provides a detailed summary of findings.
What’s next
While OpenSearch 3.6 marks a significant leap in streamlining search quality, it is only the beginning of a broader vision for autonomous relevance optimization. We are planning future enhancements to make relevance engineering more dynamic, expansive, and increasingly autonomous.
Closing the loop with online testing
Currently, OpenSearch Relevance Agent excels at offline evaluation using historical data. Our next major milestone is extending the improvement cycle into the online production environment. We are planning to enable OpenSearch Relevance Agent to orchestrate interleaving tests—a technique that blends results from different tuning strategies in real time. By analyzing user click patterns in a live setting, OpenSearch Relevance Agent will be able to capture user feedback faster than traditional A/B testing, allowing for even more rapid and precise iteration.
Expanding the optimization surface
The current version of OpenSearch Relevance Agent focuses on powerful query-DSL-level adjustments. We plan to expand the agent’s toolbox to include complex index-level operations and advanced optimization techniques:
- Schema evolution: Recommending and executing changes to mappings, such as adding sub-fields or changing tokenizers.
- Vector and hybrid search tuning: Optimizing k-NN parameters and balancing lexical and semantic weights in hybrid search architectures.
- Automated Learning to Rank (LTR): Training and deploying sophisticated ranking models that use machine learning to weigh hundreds of features simultaneously. OpenSearch Relevance Agent will help automate the feature engineering and model training lifecycle, moving beyond manual boost functions to a fully optimized ranking experience.
Universal data connectivity using MCP
While OpenSearch Relevance Agent is optimized to use OpenSearch’s native UBI functionality, we recognize that every organization has a unique data platform. Our vision is to make OpenSearch Relevance Agent a truly data-agnostic engine by using the MCP server to connect with external signals—treating platforms like Google Analytics, Matomo, Snowflake, or BigQuery as modular data sources. This ensures that OpenSearch Relevance Agent can ground its recommendations in whatever source of truth you use to track user success, transforming it from a specialized plugin into a universal relevance orchestrator.
How you can contribute
OpenSearch Relevance Agent is an open-source project that is part of the OpenSearch Project platform, and it grows through community contribution. Whether you want to add support for a new relevance feature, improve the relevance agent, or simply share feedback from your experience, we want to hear from you. Clone the repository, try it with your own data, and share your results with the community.
⭐ Star us and get involved in the OpenSearch Agent Server repository on GitHub
Questions? Join the conversation in the OpenSearch community forum and Slack.
Acknowledgments
We would like to extend our sincere gratitude to the following contributors for their valuable contributions to this project:
- Sean Zheng
- Janelle Arita
- Mingshi Liu
- Jiaping Zeng
- Eric Pugh
- David Mackey
- Andreas Wagenmann
- Craig Perkins
Your dedication, expertise, and collaborative spirit have been instrumental in making this project successful. Thank you for your time and contributions.

