
OpenSearch 3.3 represents another major step forward in performance and innovation. The first version in the 3.x series, OpenSearch 3.0, which was released on May 6, 2025, delivered a 10× improvement in search performance and a 2.5× improvement in vector performance. Building on that foundation, the latest 3.3 release, launched on October 14, 2025, adds further enhancements in query processing, indexing, and artificial intelligence and machine learning (AI/ML) capabilities.
In OpenSearch 3.3, query latencies have decreased on average ~11× compared to OpenSearch 1.3 on our standard Big5 benchmark suite. These improvements result from numerous enhancements, including a new high-performance gRPC transport layer, smarter query execution strategies, optimized data structures for aggregations, and advanced vector processing optimizations.
Vector search indexing delivered major improvements in OpenSearch 3.3, including ~9× faster indexing speed, ~3× storage reduction, 55% improvement in vector search latencies, and 40% reduction in merge times compared to OpenSearch 2.x versions. With GPU-based vector index acceleration, the vector engine now supports index builds for all compression and vector data types.
In this blog post, we’ll provide a detailed update of OpenSearch 3.3’s performance improvements, focusing on search query latency, indexing throughput, and emerging workloads such as vector search and hybrid (semantic and lexical) search. To ensure transparency and real-world relevance, we’ll present our benchmarking results conducted using the Big5 workload. Finally, we’ll share our 2026 roadmap, which outlines plans to continue advancing performance across all areas.
Query performance improvements in OpenSearch 3.3
OpenSearch 3.3 extends the performance improvements made throughout the 2.x series, as shown in the following graph. Compared to OpenSearch 1.3, the geometric-mean query latency is reduced by ~91% across key query types, corresponding to ~11× faster queries. Even compared to more recent 2.x versions, OpenSearch 3.3 shows ~33% gains over OpenSearch 2.19 on the Big5 benchmark workload.
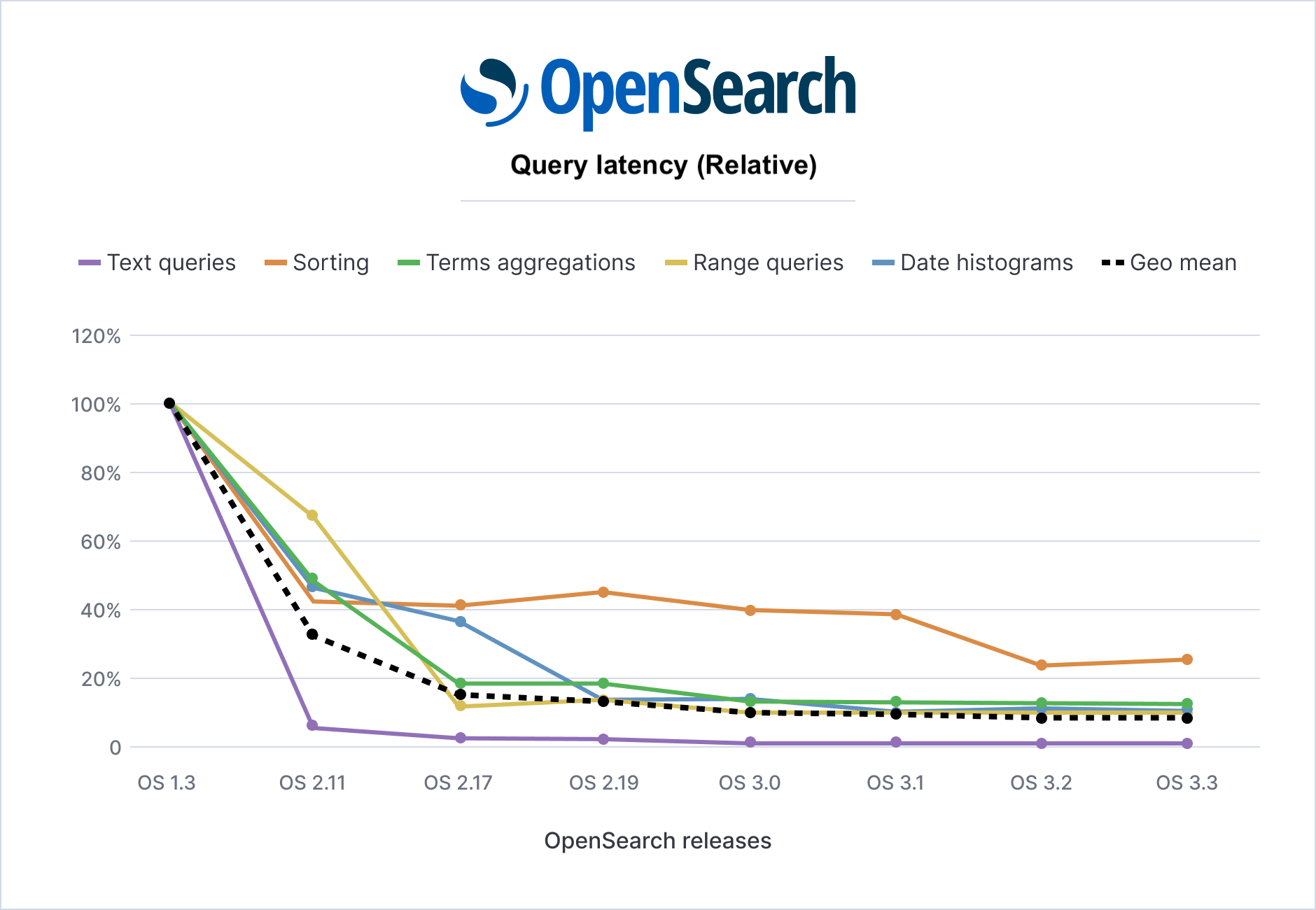
The following table summarizes latency benchmarks across OpenSearch versions 1.3.18 through 3.3.
| Query type | OS 1.3.18 | OS 2.11 | OS 2.13 | OS 2.17 | OS 2.19 | OS 3.0 | OS 3.1 | OS 3.2 | OS 3.3 | |
|---|---|---|---|---|---|---|---|---|---|---|
| Big 5 areas mean latency, ms | Text queries | 59.51 | 41.05 | 27.61 | 21.77 | 8.22 | 8.3 | 6.31 | 6.85 | 6.39 |
| Sorting | 17.73 | 8.14 | 7.53 | 7.26 | 7.96 | 7.03 | 6.82 | 4.23 | 4.5 | |
| Terms aggregations | 609.43 | 1316 | 291 | 113 | 112.08 | 79.72 | 79.74 | 77.47 | 78.52 | |
| Range queries | 26.08 | 16.91 | 17.33 | 3.17 | 3.67 | 2.68 | 2.61 | 2.61 | 2.64 | |
| Date histograms | 6068 | 5168 | 357 | 160 | 159.57 | 85.21 | 95.39 | 92.22 | 91.2 | |
| Aggregate (geo mean) | 159.04 | 130.9 | 51.84 | 24.63 | 21.21 | 16.04 | 15.36 | 14.01 | 14.03 | |
| Speedup factor, compared to OS 1.3 (geo mean) | 1.0 | 1.21 | 3.07 | 6.46 | 7.50 | 9.92 | 10.35 | 11.35 | 11.34 | |
| Relative latency, compared to OS 1.3 (geo mean) | 100% | 82.31% | 32.60% | 15.49% | 13.34% | 10.09% | 9.66% | 8.81% | 8.82% | |
The Aggregate (geo mean) row shows the geometric mean latency (ms) across all Big5 benchmark operations by OpenSearch version (lower is better).
The Speedup factor, compared to OS 1.3 (geo mean) row shows the speedup factor compared to OpenSearch 1.3 (higher is better).
The Relative latency, compared to OS 1.3 (geo mean) row shows relative latency as a percentage of OpenSearch 1.3 performance (lower is better).
Key performance improvements
OpenSearch 3.3 introduces several major performance enhancements, along with improvements added incrementally in 3.0, 3.1, and 3.2. The following are the most impactful changes implemented since the last performance blog post:
- New gRPC/protobuf transport layer: OpenSearch 3.3 uses the high-performance gRPC transport layer, generally available in 3.2, for efficient inter-node communication. The gRPC module replaces the previous REST/JSON APIs with compact Protocol Buffers, reducing payload sizes and processing overhead. This transport is used for performance-critical operations such as bulk indexing and k-NN (vector) search. Initial benchmarks of gRPC in OpenSearch Benchmark show 3–4% lower service latencies, ~50% reduction in client-side processing time, and ~20% higher throughput for vector search workloads. Beyond these immediate gains, the gRPC layer will enable more efficient client integrations and multi-node query parallelism in the future. Special thanks to Uber, a premier member of the OpenSearch Foundation, for contributing to this feature.
- Optimized sorting with the approximation framework: OpenSearch 3.2 closed a long-standing gap in pagination performance by adding efficient support for
search_afterqueries. Previously, deep pagination withsearch_afterfell back to inefficient linear scans in Lucene. In OpenSearch 3.2 and later, the engine convertssearch_afterparameters into range queries, enabling Lucene’s optimized BKD tree traversal for sorted data. The results are dramatic: in a time-series benchmark on the Big5 dataset, p90 query latency dropped from ~185 ms to ~8 ms when paginating a timestamp field usingsearch_after(for both ascending and descending sorts). Similarly, on the OpenSearch Benchmark HTTP logs dataset, the p90 latency for a descending timestamp sort decreased from ~397 ms to ~7 ms. This ~50× improvement makes dashboards and deep pagination queries significantly more responsive. For more information, see the OpenSearch approximation framework blog post. - Concurrent search thread balancing: OpenSearch 3.0 introduced concurrent segment search, allowing costly queries to run in parallel across index segments. In OpenSearch 3.3, the scheduler was improved to distribute work more evenly across threads. Previously, segments were assigned in a round-robin manner without considering size, which could leave one thread processing far more documents than others. The new approach uses a greedy load-balancing strategy: segments are sorted by size and assigned to the least-burdened thread group, equalizing work across threads. This maximizes CPU utilization, reduces idle time, and delivers more consistent latencies for concurrent queries. In practice, this optimization further reduces tail latencies by 3–5% for heavy aggregation queries under concurrency.
- Aggregation optimizations: OpenSearch has made a series of enhancements to accelerate analytical queries:
- Star-tree aggregations: First introduced in 2.19, the star-tree index pre-aggregates metrics in order to accelerate analytics queries. In OpenSearch 3.3, star-tree support is extended to multi-term aggregations, providing speedups in certain log analytics scenarios. Benchmarks show that using star-tree indexes for multi-term queries can reduce latency by ~3× on high-cardinality keyword or numeric fields and achieve up to ~40× improvement in complex queries. For example, latency for a numeric term query combined with a numeric aggregation decreases from ~6 s to ~150 ms. These improvements result from using pre-aggregated buckets to eliminate redundant per-document processing.
- Rare terms aggregations: OpenSearch 3.3 includes a community-contributed optimization for rare terms aggregations that can skip unnecessary processing under certain conditions. When an index has no deleted documents, the engine can use stored summary information to identify and skip common terms, finishing the query earlier. This results in up to 50% faster query times for rare-term searches.
- Composite terms aggregations: OpenSearch 3.2 improved the performance of composite aggregations, which are used to paginate through large sets of terms. By reusing objects and optimizing field mappings, this update provides a modest ~5% speedup for composite terms aggregation queries and reduces garbage collection overhead for large aggregations.
- Skip lists for date histograms: Time-series aggregations received a major performance boost with the new skip list index. Skip lists are lightweight, pre-aggregated data structures that store summary information about data ranges, allowing OpenSearch to quickly skip over irrelevant sections during queries. Originally introduced as an optional feature in OpenSearch 3.0 and expanded to all numeric fields in OpenSearch 3.2, skip lists are now enabled by default for timestamp fields (like the
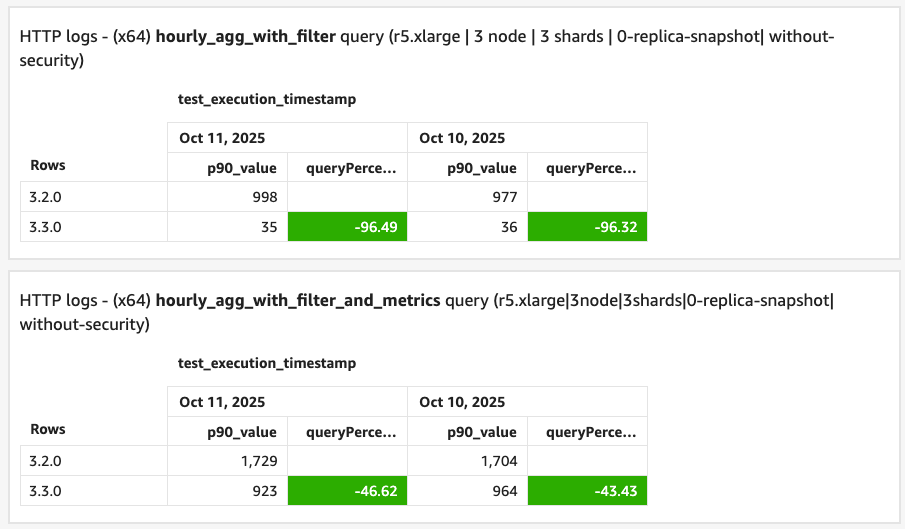
@timestampfield in log data) in version 3.3. When running date histogram queries, OpenSearch can use skip lists to bypass time ranges that contain no data or do not match filters instead of scanning every document. This is particularly effective for filtered date histogram queries. We tested this feature using new benchmark queries on a dataset with 116 million HTTP log records. The results are shown in the following image.
 The specific performance improvements achieved with skip lists include:
The specific performance improvements achieved with skip lists include:
- An hourly aggregation with filter query achieved a 96% reduction in latency with skip lists (query time was only 4% of the original).
- An hourly aggregation with filter and metrics query (computing additional stats per bucket) achieved a 46% reduction in latency from skip list optimizations.
- Streaming aggregations with Apache Arrow: OpenSearch 3.3 introduces an experimental streaming approach for processing aggregations using Apache Arrow and Apache Arrow Flight technologies. Instead of waiting for each processing phase to complete before starting the next, streaming aggregations can deliver partial results as they become available. This reduces memory usage and improves response times for complex aggregations. Currently available under an experimental feature flag, this streaming approach supports numeric terms and cardinality count aggregations. Early benchmarks show up to 2x faster response times for aggregations on very large datasets. We plan to enable this feature by default in future releases and expand it to support more query types.
- Updated search engine core: OpenSearch 3.3 runs on Apache Lucene 10.3, upgraded from Lucene 10.1 in OpenSearch 3.0. This update brings numerous low-level performance improvements and bug fixes from the Lucene community, including enhanced segment merging, more efficient compression, and faster query processing. Paired with an updated Java runtime (JDK 24 for OpenSearch 3.3.1), these changes allow OpenSearch to use the latest enhancements in both the search engine library and JVM for improved speed and efficiency.
Query performance improvements by type
OpenSearch 3.3 delivers faster performance across all common query types compared to earlier versions. On average (geometric mean across queries), overall latency is reduced by ~11× compared to OpenSearch 1.3: queries that took 160 ms in OpenSearch 1.3 now complete in about 14 ms in OpenSearch 3.3. The performance improvements span all major query categories, with each delivering substantial gains:
- Text queries: Text search operations are ~89% faster in OpenSearch 3.3 compared to 1.3. A typical full-text query that took ~60 ms now completes in ~6.4 ms. These improvements result from optimizations like the
match_only_textfield type and enhanced query execution. - Terms aggregations: Aggregating high-cardinality terms (such as finding the top-k most frequent terms) is ~87% faster than in 1.3, with latencies decreasing from ~609 ms to ~79 ms in our tests. The 2.x series introduced major optimizations in this area, and 3.x extends them with features like star-tree and streaming aggregations for even more efficient performance on large aggregations.
- Date histograms: Time histogram queries (for example, bucketing events by hour or day) show ~98% lower latency in OpenSearch 3.3 compared to 1.3. In our benchmark, a date histogram on a ~100 GB log index dropped from ~6 seconds in OpenSearch 1.3 to ~0.09 seconds in OpenSearch 3.3—a ~60× speedup. These gains are driven by features such as skip list indexing and concurrent segment processing, which make time-based aggregations extremely fast.
- Range queries: Numeric range filtering (such as finding all values between 2 numbers) executes ~90% faster in OpenSearch 3.3 than in 1.3, decreasing from 26 ms to ~2.6 ms. Much of this improvement originated in OpenSearch 3.0, when the new range query approximation framework became generally available. By using indexed bounds and block skipping, the framework avoids scanning irrelevant data. Combined with other engine optimizations, this feature makes range filters highly efficient in OpenSearch 3.3.
- Sorting queries: Sorted queries (such as ordering results by timestamp or numeric field) are 75% faster in OpenSearch 3.3 compared to 1.3, with response times decreasing from ~17.7 ms to ~4.5 ms on average. Most of this performance gain originates from restoring Lucene’s optimized time-series sorting in 3.x and from the previously described
search_afteroptimizations introduced in OpenSearch 3.2, which significantly accelerate deep pagination.
AI/ML and vector search advancements
AI/ML workloads, such as vector search and hybrid semantic search, have been a major focus for OpenSearch 3.x. These applications require intensive processing for high-dimensional vector calculations and often handle large datasets, making performance improvements especially valuable for reducing costs and increasing throughput. OpenSearch 3.3 delivers several important advancements in this area:
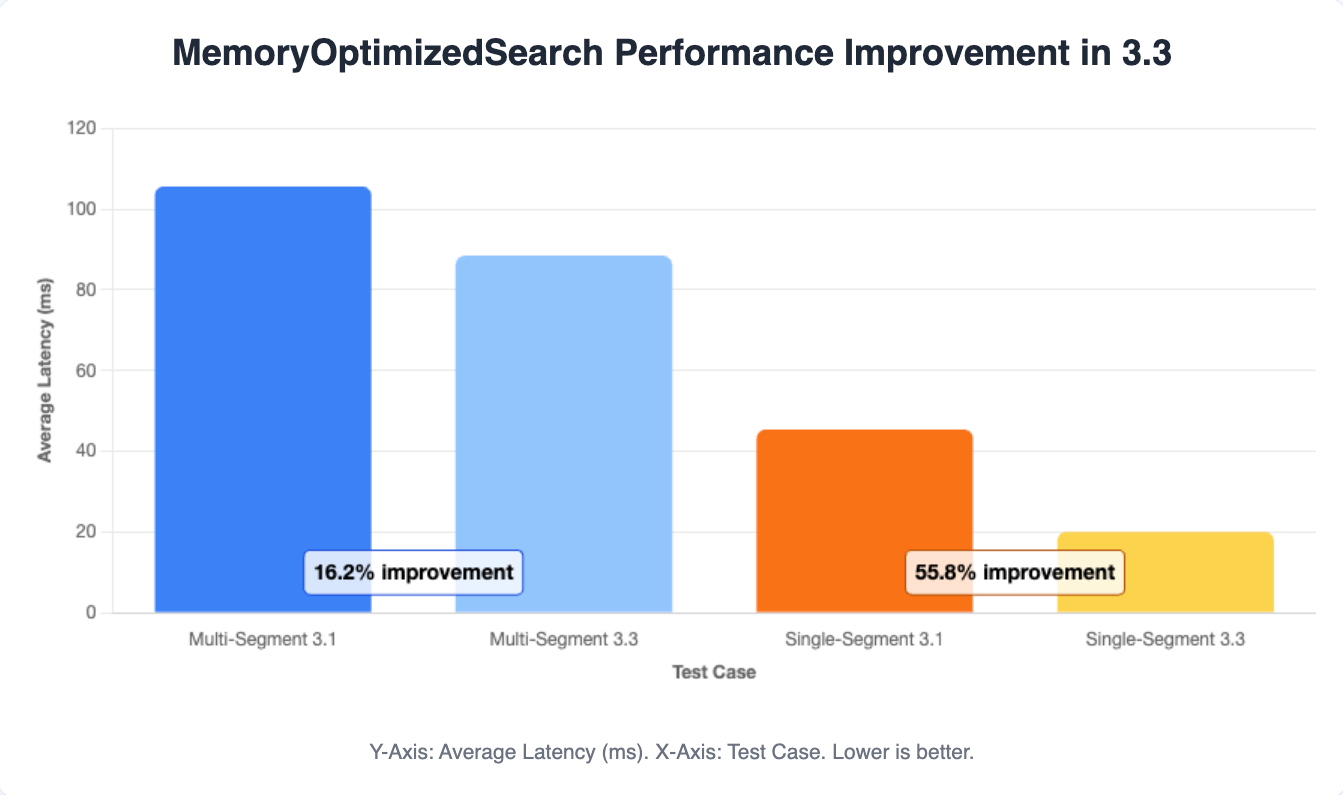
- Faster k-NN vector search (FP16 optimization): OpenSearch’s k-NN engine (in the k-NN plugin, which integrates libraries like Faiss) introduced a new optimization in OpenSearch 3.3 to accelerate memory-optimized vector searches. Previously, when using half-precision (FP16) vectors, the JVM lacked native FP16 support, requiring conversion to FP32 before distance computations—adding memory and compute overhead. OpenSearch 3.3 eliminates this bottleneck by passing raw FP16 vector data directly to native C++ routines, enabling SIMD-accelerated distance calculations without FP32 conversion. This removes redundant copying and avoids widening the data, greatly improving throughput. In tests, these changes, combined with an optimistic parallel search strategy, yield a ~16.2% performance improvement in multi-segment vector query latency, with only a minimal ~2% reduction in recall accuracy. For single-segment (in-memory) queries, performance improves by 55.8%, reducing the performance difference between OpenSearch and Faiss low-level vector libraries. In practice, this translates to faster approximate nearest neighbor (ANN) searches for ML applications without sacrificing result quality. The performance improvements are shown in the following image.
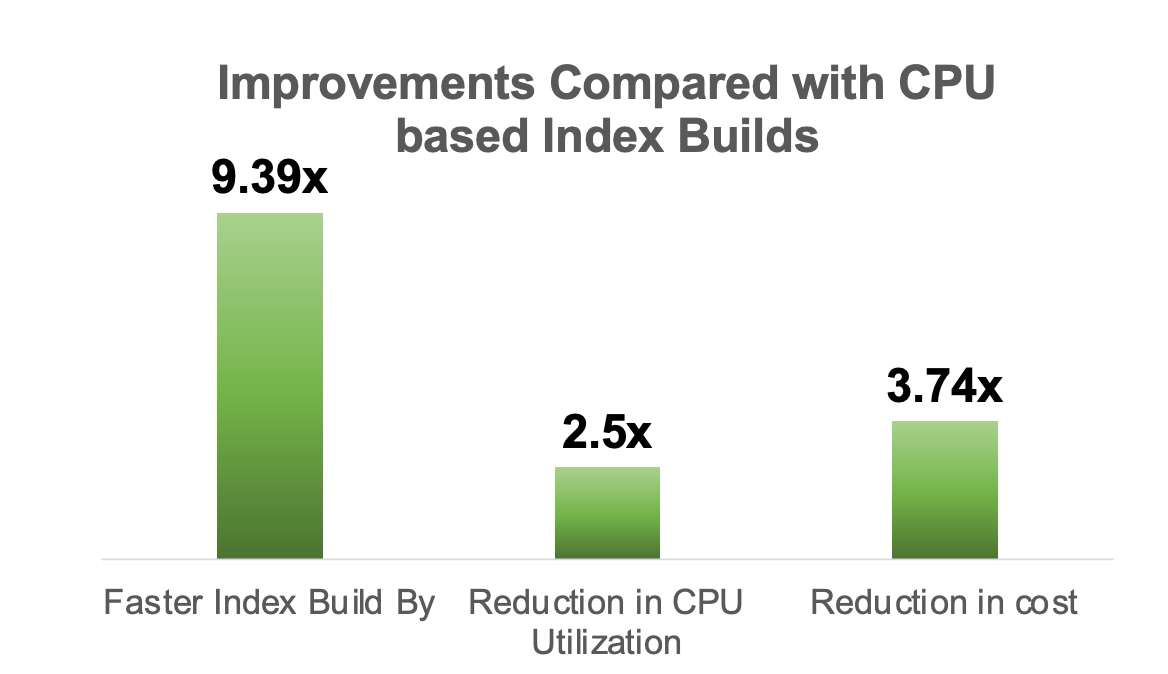
- GPU performance: OpenSearch’s vector engine gained additional features beyond core performance improvements, including GPU-accelerated k-NN indexing (generally available in OpenSearch 3.1) for 9× faster index builds. GPU-based index acceleration supports byte data types, binary data types, and quantized indexes with multiple compression ratios (2×, 8×, 16×, and 32× compression) for both in-memory and on-disk modes. The performance improvements compared to CPU-based index builds are shown in the following image.
Hybrid search
OpenSearch supports hybrid search queries that combine traditional keyword search with semantic vector search, allowing you to find documents using both exact keywords and semantic similarity. The hybrid search feature has been continually optimized for better performance. OpenSearch 3.1 introduced a custom hybrid bulk scorer that takes full advantage of concurrent segment search, resulting in up to 65% faster responses and 3.5× higher throughput for hybrid queries compared to previous OpenSearch versions. The throughput improvements are shown in the following image.
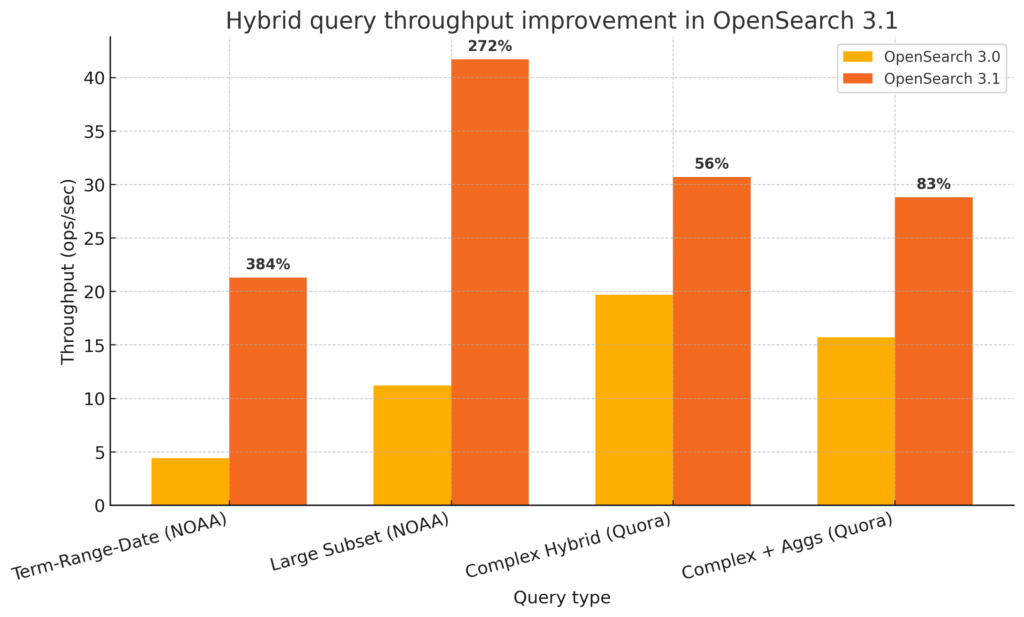
OpenSearch 3.3 further builds on this enhancement by streamlining the query execution phase with a new QueryCollectorContextSpec class that allows hybrid query logic to integrate directly into the search collector, eliminating unnecessary processing layers. This delivers an additional 20% latency improvement for hybrid searches that include lexical subqueries and up to 5% improvement for combined lexical and vector queries. The latency improvements are shown in the following image.
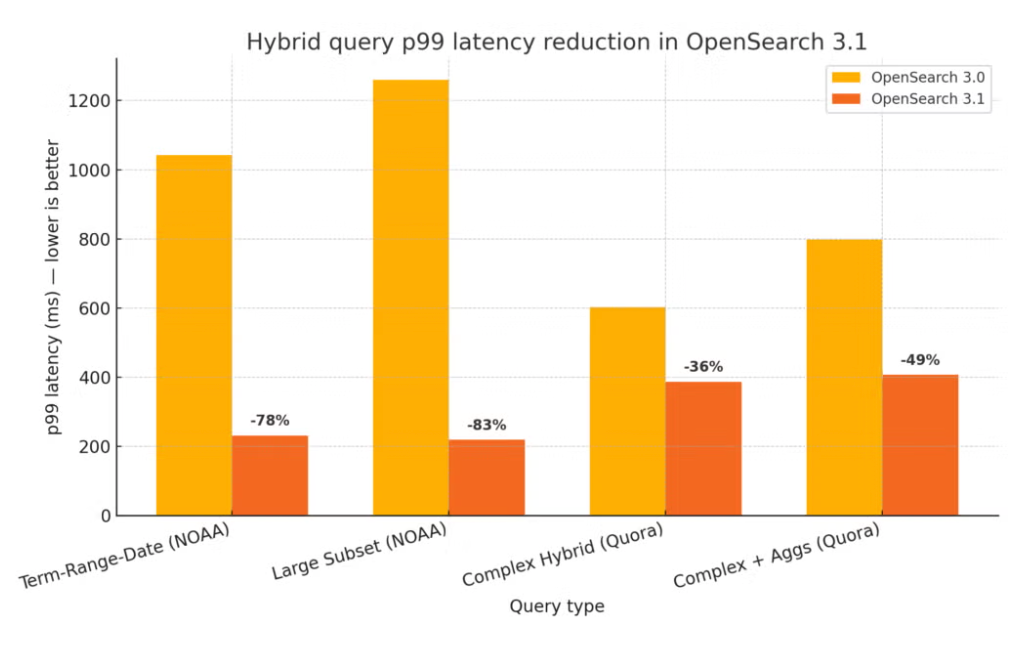 These enhancements make hybrid search more efficient and benefit use cases like enterprise search and question answering, in which result relevance depends on both exact keyword matches and broader semantic understanding.
These enhancements make hybrid search more efficient and benefit use cases like enterprise search and question answering, in which result relevance depends on both exact keyword matches and broader semantic understanding.
Indexing and ingestion performance
OpenSearch 3.3 delivers not only faster queries but also significant improvements to data ingestion and storage efficiency, helping you index more data faster while reducing storage costs:
- Derived source for storage savings: A major enhancement introduced in OpenSearch 3.2 is derived source indexing, which OpenSearch 3.3 uses to significantly reduce index size. In a typical OpenSearch index, each document’s original JSON
_sourceis stored in full, alongside indexed terms and columnar data (doc values) for each field, leading to substantial storage overhead. Derived source mode eliminates this duplication by omitting the stored_sourceat index time and reconstructing the original document on demand from the per-field values. Crucially, this preserves full functionality—searches, highlights, reindexing, and updates still work as usual because the source can be dynamically regenerated. The benefit is a much smaller index: by avoiding storage of raw JSON, you can achieve roughly 2× storage savings. In our benchmarks, enabling derived source reduced index storage by ~58% on a large dataset, with no loss of query capability. A smaller index also improves shard recovery times and reduces disk I/O, resulting in better overall performance. - Faster indexing throughput: An additional benefit of derived source is faster ingestion. By not storing the full
_source, OpenSearch performs less work per document (less data to write and compress). In practice, we observed indexing throughput improvements of up to ~18% with derived source enabled. Merge times also dropped by 20–48%, as the engine writes smaller segments. As a result, OpenSearch 3.3 is not only more cost efficient due to smaller indexes but also faster, keeping indexing pipelines efficient. - Other ingestion enhancements: OpenSearch continues to streamline ingestion pipelines for AI/ML use cases. For example, the 3.x series introduced an optimization to the
text_embeddingingest processor: a configurable option used to skip embedding inference for unchanged inputs, avoiding redundant model calls. This simple change can reduce ingestion latency by up to 70% in workflows that enrich documents with embeddings, as embeddings are not recomputed when a document is reindexed without changes. Combined with features like asynchronous batch processing for ML models, OpenSearch makes it easier to ingest and enrich data at scale without bottlenecks.
OpenSearch benchmarking improvements
OpenSearch Benchmark has become the standard performance testing suite for OpenSearch since its initial major release in May 2023. The community’s launch of OpenSearch Benchmark 2.0 marks a significant evolution, offering enhanced capabilities that address key testing limitations and expand benchmarking possibilities across multiple dimensions.
OpenSearch Benchmark 2.0 introduces five transformative features that improve performance testing workflows. Red-line testing identifies cluster capacity limits in a single test run using real-time monitoring and self-adjusting load mechanisms. Synthetic data generation allows organizations to create privacy-compliant datasets at scale from an OpenSearch index mapping, supporting complex workloads such as time-series data and vector distributions. Streaming ingestion enables continuous document ingestion at high rates, scaling to multiple terabytes daily from a single host without requiring locally stored static data. Enhanced visualization tools convert raw test results into shareable reports for easier analysis and collaboration. Additionally, the suite now supports gRPC transport and looped bulk ingestion.
The official workload collection has also been enhanced with two notable additions: the Big5 workload now includes Piped Processing Language (PPL) format support, and a new ClickHouse workload based on the ClickBench dataset includes Yandex.Metrica web analytics data. This workload measures OpenSearch performance using PPL queries covering common web analytics operations such as aggregations, filtering, sorting, and complex analytical queries, providing deeper insights into feature performance across OpenSearch.
Roadmap for 2026
Based on the public roadmap, 2026 will bring significant architectural evolution to OpenSearch, with major initiatives spanning streaming query processing, composable engine design, enhanced gRPC APIs, and advanced vector search capabilities.
Streaming query architecture
The path forward focuses on enabling streaming aggregations by default in milestone 3.5, as outlined in this proposal. This work will close remaining gaps in areas such as query planning, request caching, top N computation, virtual threads, and benchmarking.
In parallel, the roadmap continues to expand support for columnar formats as a first-class component to improve memory efficiency, introduce distributed multi-level reduce for higher accuracy, enable streaming search for expensive queries, and drive broader plugin adoption.
Key technical themes include block-based processing using the Apache Arrow format, integration with the composable query engine execution model (described in the following sections), and incremental migration toward schema-aware columnar operations across both aggregations and search. The overarching goal is to improve performance by reducing bottlenecks inherent in the traditional request–reply architecture.
OpenSearch composable query engine architecture
OpenSearch is proposing a major architectural transformation to evolve from its tightly coupled Lucene foundation into a composable query engine that supports pluggable execution engines and file formats. This addresses current limitations, such as memory and storage bottlenecks in aggregations on large datasets, and duplicated logic across query languages (query domain-specific language [DSL], SQL, and PPL), each implementing its own expression engine. The vision centers on language front ends translating to a common logical plan using Substrait Intermediate Representation, a central planning layer performing cost-based optimization, and pluggable execution engines (currently evaluating DataFusion and Velox) that accept logical plans and generate Apache Arrow responses. The default Lucene-based aggregation framework and SearchService remain intact, with new plugin hooks—all implemented as opt-in plugins to preserve backward compatibility. Community discussion has shown strong support and active contributions, including ByteDance offering their OLAP plugin with a new computing framework, suggestions to use Velox4J for Velox integration, and interest in alternative storage engines such as segmentless designs for efficient in-place updates, particularly beneficial for vector search.
gRPC-based search API
Work continues on closing the gap between the REST API and gRPC, including additional benchmarks demonstrating gRPC benefits. This effort covers 50+ aggregation types—such as date_histogram, terms, cardinality, stats, percentiles, geographic aggregations, and others, which are being added to the protobuf schema and implemented in the gRPC transport module. This ensures that the gRPC API can fully support the range of aggregation capabilities available in OpenSearch for analytics and data exploration workloads.
Core search engine performance optimizations
OpenSearch continues to explore low-level engine improvements that accelerate query and aggregation performance. Key initiatives in this area include:
- Skip-list-based optimization: OpenSearch 3.4 will expand date histogram support so that they work as a sub-aggregation with range and auto date histograms. The next step is modifying the logic to allow sub-aggregations while tracking multiple owning bucket ordinals. This logic will be incorporated into
minandmaxaggregations, accelerating them by using pre-aggregated data fromDocValuesSkipper. - Using the Lucene Bulk Collection API to accelerate aggregation: We are exploring Lucene’s new bulk collection APIs to improve aggregation performance, using features like
LeafCollector#collectRangein Lucene 10.3 and upcoming 10.4 APIs such asNumericDocValues#longValuesandDocIdStream#intoArray. Bulk processing reduces virtual call overhead and may allow pushing retrieval down to the codec level for dense document scenarios. - Intra-segment concurrent search: We are working on enabling intra-segment concurrent search, a capability introduced in Lucene 10 that splits individual segments by document ID for concurrent processing across multiple threads. This provides finer-grained parallelism beyond the existing concurrent segment search feature. The goal is to apply this optimization to all queries and aggregations that support concurrent segment search without performance degradation. Primary areas of focus include configuring intra-segment concurrency for end users, improving the slicing mechanism so that it evenly distributes work across threads, and updating custom collectors and collector managers to handle the new concurrency model. These changes aim to improve CPU utilization and query performance for large segments.
- Missing terms aggregator: This extends the rare terms aggregator optimization in OpenSearch 3.3, which achieved a 50% performance improvement by using precomputed values under certain conditions.
Vector search
OpenSearch continues to enhance its vector search capabilities to support more efficient, scalable, and extensible workflows for high-dimensional data. Key initiatives include:
- Adding support for BFloat16 with Faiss scalar quantizer for extended range: Adding BFloat16 support to the Faiss scalar quantizer will allow the k-NN plugin to overcome the range limitation of the existing FP16 implementation. FP16 restricts input vectors to [-65,504, 65,504] and prevents it from being a default data type, despite its 50% memory reduction and comparable performance to FP32. BFloat16 (SQbf16) provides the same extended range as FP32 (approximately ±3.4 × 10³⁸) while maintaining 50% memory savings by trading off precision, supporting 2–3 decimal values (7 mantissa bits). The k-NN engine can use Intel AVX512 BF16 instruction sets for hardware-accelerated performance on newer processors. This makes 16-bit quantization viable for a wider range of vector search use cases without range constraints.
- Making memory-optimized search the default: In OpenSearch 3.3, the k-NN plugin achieved significant improvements with memory-optimized search by combining the HNSW graph traversal algorithm from the Lucene library with C++ bulk SIMD-based distance computation. Future optimizations include adding warmup functionality for memory-optimized search indexes to reduce tail latencies and making FP16 the default with memory-optimized search to reduce memory footprint by 50%.
- Enhancing disk-based vector search: In OpenSearch 2.17, the k-NN plugin introduced disk-based vector search support, allowing searches to run in lower-memory environments. Version 2 of disk-based vector search will reduce disk reads by reordering vectors on disk to maximize the number of vectors retrieved per disk access using techniques like Bi-partite Graph Partitioning (BPGP) and Gorder Priority Queue (Gorder-PQ). Additionally, this version will include different variants of Better Binary Quantization (flat and approximate search) in the vector engine.
- Accelerating indexing and search performance: OpenSearch continues to use hardware acceleration with new SIMD instructions like avx512_fp16, BFloat16, and ARM SVE in order to improve search performance on x86 and ARM instances. For remote index builds using GPUs, planned optimizations include reducing index file transfer between GPU machines, which is expected to improve GPU-based index builds by 2×.
- Making the OpenSearch vector engine extensible: Moving vector search interfaces from the k-NN plugin to OpenSearch core will address extensibility challenges and plugin dependencies in the growing vector search environment. Currently, the k-NN plugin (supporting Lucene and Faiss) and the newer JVector plugin operate with their own implementations but lack standardized interfaces. This proposal elevates common vector search interfaces into OpenSearch core, enabling better extensibility for new vector engines, eliminating the hard dependency of the Neural Search plugin relying directly on the k-NN plugin, and allowing users to choose any vector plugin (k-NN, JVector, or future engines) with the Neural Search plugin while providing a standardized contract that simplifies onboarding new vector engines and encourages innovation.
Appendix: Benchmarking methodology
All performance comparisons were conducted using a repeatable process based on the OpenSearch Benchmark tool and the Big5 workload. Benchmarks covered match queries, terms aggregations, range filters, date histograms, and sorted queries. The dataset (~100 GB, 116 million documents) reflects time-series and e-commerce use cases.
Environment: Tests were run on a single-node OpenSearch cluster using c5.2xlarge Amazon Elastic Compute Cloud (Amazon EC2) instances (8 vCPUs, 16 GB RAM, 8 GB JVM heap). Default settings were used unless noted. Indexes had one primary shard and no replicas to avoid multi-shard variability. Documents were ingested chronologically to simulate time-series workloads.
Index settings: We used Lucene’s LogByteSizeMergePolicy and did not enable explicit index sorting. In some tests, a force merge was applied to normalize segment counts (for example, 10 segments in both 2.19 and 3.3) in order to ensure a fair comparison.
Execution: Each operation was repeated multiple times. We discarded warmup runs and averaged the next three runs. Latency metrics included p50, p90, and p99; throughput was also recorded. OpenSearch Benchmark was run in throughput-throttled mode to record accurate query latency for each operation type.
Software: Comparisons used OpenSearch 2.19.1 (Java 17) and 3.3.1-beta (Java 24, Lucene 10.3.1). Only default plugins were enabled. Vector benchmarks used Faiss + HNSW using the k-NN plugin, with recall measured against brute-force results.
Metrics: Big5 median latency is the simple mean of the five core query types. Aggregate latency is the geometric mean, used for overall comparison. Speedup factors are reported relative to OpenSearch 1.3 where noted.
| Buckets | Query | Order | OS 1.3.18 | OS 2.19 | OS 3.0 | OS 3.1 | OS 3.2 | OS 3.3 |
|---|---|---|---|---|---|---|---|---|
| Text queries | query-string-on-message | 1 | 332.75 | 4 | 4 | 4 | 5 | 5 |
| query-string-on-message-filtered | 2 | 67.25 | 11 | 11 | 11 | 11 | 11 | |
| query-string-on-message-filtered-sorted-num | 3 | 125.25 | 26 | 27 | 18 | 20 | 19 | |
| term | 4 | 4 | 4 | 4 | 2 | 2 | 2 | |
| Sorting | asc_sort_timestamp | 5 | 9.75 | 7 | 7 | 5 | 5 | 6 |
| asc_sort_timestamp_can_match_shortcut | 6 | 13.75 | 7 | 7 | 6 | 7 | 7 | |
| asc_sort_timestamp_no_can_match_shortcut | 7 | 13.5 | 7 | 7 | 6 | 6 | 6 | |
| asc_sort_with_after_timestamp | 8 | 35 | 150 | 168 | 150 | 4 | 5 | |
| desc_sort_timestamp | 9 | 12.25 | 7 | 7 | 6 | 6 | 6 | |
| desc_sort_timestamp_can_match_shortcut | 10 | 7 | 6 | 5 | 6 | 6 | 6 | |
| desc_sort_timestamp_no_can_match_shortcut | 11 | 6.75 | 6 | 5 | 5 | 5 | 6 | |
| desc_sort_with_after_timestamp | 12 | 487 | 246 | 93 | 169 | 5 | 5 | |
| sort_keyword_can_match_shortcut | 13 | 291 | 4 | 4 | 4 | 4 | 4 | |
| sort_keyword_no_can_match_shortcut | 14 | 290.75 | 4 | 4 | 4 | 4 | 4 | |
| sort_numeric_asc | 15 | 7.5 | 4 | 3 | 3 | 3 | 4 | |
| sort_numeric_asc_with_match | 16 | 2 | 2 | 2 | 2 | 2 | 2 | |
| sort_numeric_desc | 17 | 8 | 5 | 4 | 3 | 4 | 4 | |
| sort_numeric_desc_with_match | 18 | 2 | 2 | 2 | 2 | 2 | 2 | |
| Terms aggregations | cardinality-agg-high | 19 | 3075.75 | 2235 | 628 | 811 | 732 | 764 |
| cardinality-agg-low | 20 | 2925.5 | 3 | 3 | 3 | 3 | 3 | |
| composite_terms-keyword | 21 | 466.75 | 218 | 202 | 187 | 186 | 168 | |
| composite-terms | 22 | 290 | 362 | 328 | 304 | 317 | 289 | |
| keyword-terms | 23 | 4695.25 | 26 | 19 | 19 | 16 | 18 | |
| keyword-terms-low-cardinality | 24 | 4699.5 | 22 | 13 | 12 | 13 | 15 | |
| multi_terms-keyword | 25 | 0* | 734 | 657 | 650 | 622 | 668 | |
| Range queries | keyword-in-range | 26 | 101.5 | 68 | 14 | 11 | 11 | 12 |
| range | 27 | 85 | 14 | 4 | 4 | 4 | 4 | |
| range_field_conjunction_big_range_big_term_query | 28 | 2 | 2 | 2 | 2 | 2 | 2 | |
| range_field_conjunction_small_range_big_term_query | 29 | 2 | 2 | 2 | 2 | 2 | 2 | |
| range_field_conjunction_small_range_small_term_query | 30 | 2 | 2 | 2 | 2 | 2 | 2 | |
| range_field_disjunction_big_range_small_term_query | 31 | 2 | 2 | 2 | 2 | 2 | 2 | |
| range-agg-1 | 32 | 4641.25 | 2 | 2 | 2 | 2 | 2 | |
| range-agg-2 | 33 | 4568 | 2 | 2 | 2 | 2 | 2 | |
| range-numeric | 34 | 2 | 2 | 2 | 2 | 2 | 2 | |
| Date histograms | composite-date_histogram-daily | 35 | 4828.75 | 3 | 3 | 3 | 3 | 3 |
| date_histogram_hourly_agg | 36 | 4790.25 | 6 | 4 | 5 | 5 | 5 | |
| date_histogram_minute_agg | 37 | 1404.5 | 36 | 37 | 40 | 39 | 39 | |
| range-auto-date-histo | 38 | 10373 | 7899 | 1871 | 2076 | 1969 | 2041 | |
| range-auto-date-histo-with-metrics | 39 | 22988.5 | 20211 | 5406 | 6341 | 5790 | 5603 |
* multi_terms-keyword support: OpenSearch 1.3.18 recorded 0 ms service time for multi_terms-keyword. This is because multi_terms-keyword was not supported until OpenSearch 2.11.0. Mean latency calculations account for this by excluding multi_terms-keyword from the geometric mean computation for OpenSearch 1.3.18.






