
This post was imported from the Open Distro For Elasticsearch blog, a predecessor project of OpenSearch. Information reflected in this post may not be current or accurate.
Today, we released Anomaly Detection (preview) on Open Distro for Elasticsearch. We are excited to continue our work on anomaly detection as a part of Open Distro for Elasticsearch in the coming months, and invite developers in the larger search community to join in and co-develop some parts. The feature includes a nice mix of machine learning algorithms, statistics methods, systems work, visualization and UI, and enterprise primitives (for working on anomalies).
Analytics data continues to increase exponentially with time. An exponential data surge reduces the usage of a traditional analytics user workflow, which has been a set of canned queries and dashboards. This is because actionable queries require keeping track of data changes and distribution of each field over time, which is harder to achieve when data volumes increase significantly; heterogeneity (e.g., attack behavior in security traces) complicates understanding the data itself.
Our goal is to build a set of real time analytics features for Elasticsearch that makes it easier for Open Distro for Elasticsearch users to automatically mine real time patterns across data streams at ingestion. We want to provide users with an interactive and guided exploration of data without having them to worry about tuning the analytics “blackbox” that includes the models, hyperparameters and labels (with an option, however, for semi-supervised approaches). We started off by building and releasing anomaly detection as an Open Distro for Elasticsearch feature. In this blog, we discuss foundational aspects upon which anomaly detection is built: Random Cut Forest (RCF) machine learning algorithms underpinning the detection, the system architecture and workflow.
Requirements
The first step towards actionable data analytics is anomaly detection. In this document, we propose to build anomaly detection as a feature on Elasticsearch. Our goal is to build algorithms that are: (1) lightweight, i.e., streaming, (2) unsupervised, (3) accurate, (4) interactive, i.e., low training time to detect anomalies, and (5) embarassingly parallelizable and elastic. In addition, the algorithms should be able to account for (or not) seasonality in data, and be able to detect not only changes in first and second order magnitude, but also non-distributional effects such as changes in frequency content and phase. We want to support multi-dimensional detection methods. For power users, we may support “bring your own detection algorithms” and ensemble methods.
When building the system, our goal is to leverage statistical multiplexing of resources on the Elasticsearch cluster to minimize cost. The system should partition and distribute the work of doing anomaly detection across the cluster. Note that the overhead of anomaly detection will be negligible if we use lightweight streaming algorithms. Such algorithms give us control over bounding compute and memory resources for training and detection and are also embarassingly parallelizable. This will enable anomaly detection with zero additional cost (e.g., cost of adding anomaly detection nodes) on the existing ingestion and query workload. The detection system should be able to support using separate anomaly detection node(s) if desired. The system should be elastic to changes in cluster membership, and to available resources (which also makes it fault tolerant and highly available).
Actionability and Interfaces
The simplest way to do anomaly detection is to run detectors on all fields (and their combinations) in the data. While this requires zero inputs from the user, it risks generating too many false positives from the standpoint of being actionable, and sometimes, false negatives (if the fields do not describe the metric directly). It also results in wasted work (and the cost of provisioning for that work).
To generate actionable insights from real time data, we would need inputs from the user to understand what is considered actionable. Treating the anomaly detector as a blackbox, we have two places from where we can capture user intent on actionability: the input and the output to/from the detector. Two input intents are feature definitions and examples of anomalies (i.e., labeled data). Feature definitions are arbitrary functions of the fields in the data (and can be the fields themselves). An example feature definition is an error count computation on the HTTP return codes in log data, where each log line corresponds to an HTTP session in each time window. In this example, running an anomaly detector on the return codes directly would cause anomalies that can be false positives or ones hard for the user to explain. For most applications of Elasticsearch, we do not expect well-calibrated labeled examples — and using such examples without calibration can cause over/under-fitting. We instead focus on algorithms with the largest customer reach, i.e., unsupervised learning.
The output intents we can get from the user include explicit user-defined tags on the data we can use as potential labels (e.g., upgrade windows, outages); and interactive validations, where the user marks anomalies as false positives or undetected. Semi-supervised methods can be used on such user inputs. In our first version, we consider unsupervised methods, but those which can naturally be extended to be semi-supervised methods. These intents express actionability to some extent, but can easily miss windows that the user could consider actionable (because it would be tedious for the user).
Across both input and output user intents, the most useful intent is the feature definitions. We consider that in our first version. We define some terminology here. The user would define an anomaly detector that includes one or more features in an index, a periodicity for the feature computation, and data filtering criteria (if any). Each feature definition could be as simple as selecting a field, to defining an aggregation function over the field to an arbitrary script on one or more fields. Note this also implies that users can specify a multi-dimensional detector (over multiple features). For multi-dimensional detectors, the user could optionally indicate an importance parameter for one or more features. We have built both API and Kibana UI interfaces to these concepts.
The output of an anomaly detector (i.e., anomalies) can be consumed by the user using Open Distro for Elasticsearch Alerts, or can be browsed using Kibana (including historic anomalies and feature timeseries). We want to enable an interactive experience when defining a detector using Kibana — the user should be able to interactively add/modify feature definitions and see changes in anomalies detected (along with the feature timeseries) in real time. We divide the design discussion into algorithms and systems aspects.
Building on the Random Cut Forest Algorithm
There are several unsupervised learning approaches to anomaly detection: from the traditional statistical timeseries methods to machine learning (e.g., nearest neighbor, clustering, subspace or spectral methods, density estimation, including ensemble methods) [6]. We focus on the latter, since we are also interested in non-distributional changes in data (frequency content and phase). Anomaly detections by many of the machine learning methods are hard to explain for the user and compute-heavy.
We restrict to a specific class of ensemble methods based on random forests. Random forests have been used successfully for lightweight density estimation. The Isolation Forest (2008) method [1] uses random forests to isolate anomalous data. Isolation Forest recursively partitions the hyperspace of features to construct trees (the leaf nodes are feature samples), and assigns an anomaly score to each data point based on the sample tree heights. It is a batch processing method. The Random Cut Forest (RCF, 2016) method [2] adapted Isolation Forest to work on data streams with bounded memory and lightweight compute. RCF incrementally updates the forest on each feature sample and interleaves training and inference. RCF also emits an anomaly score for each feature sample. The RCF estimator has been proven as it have been used in production settings, for example Amazon Kinesis Analytics [3], Quicksight [4] and SageMaker [5]. Using data shingling, RCFs can detect non-distributional anomalies such as frequency and phase changes. RCFs scale to high-dimensional data streams.
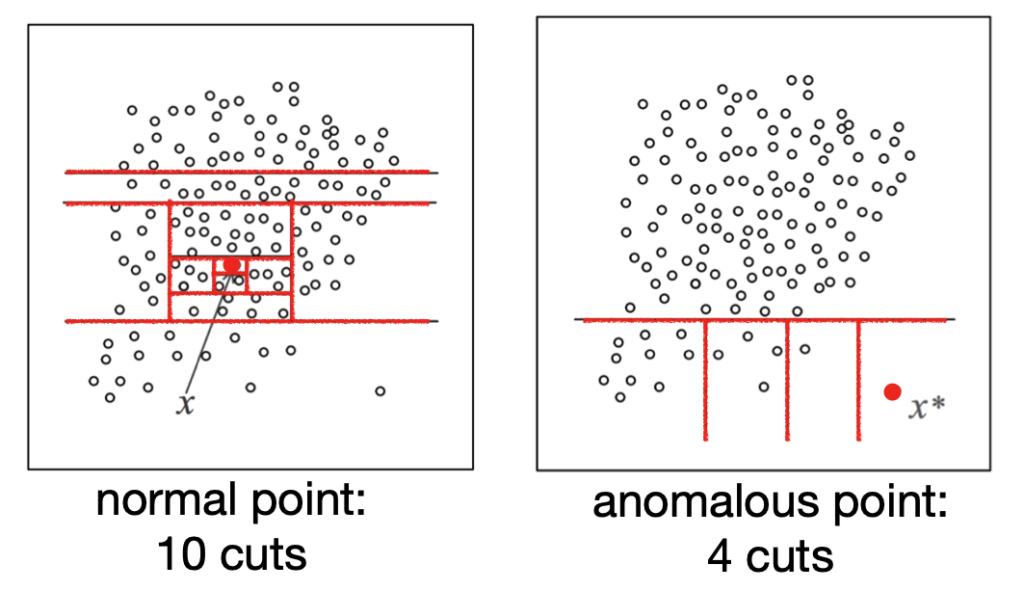
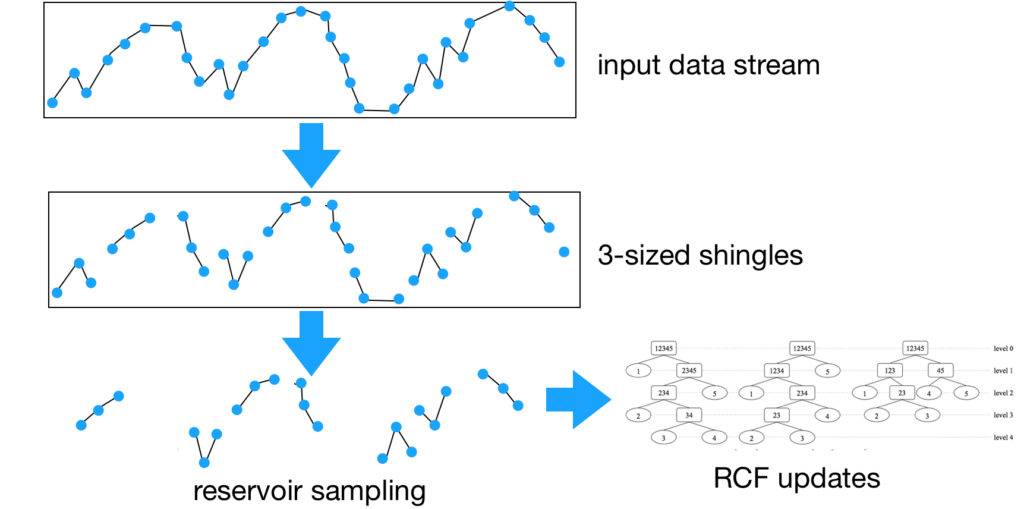
Putting RCFs to practice for real time anomaly detection in a “set it and forget it” environment requires additional work; we list them down here. First, RCFs emit an anomaly score that is hard to reason about for the user, its magnitude is a function of the data timeseries on which the RCF is trained. We need an additional learning primitive that continuously learns the baseline anomaly score distribution to detect large score values it is a classifier function that maps the anomaly score to a boolean outcome (anomaly or not). Note that this classifier is different from RCF itself. RCF isolates anomalies (i.e., not the baseline) and gives a score timeseries that captures and quantifies anomalous events; the classifier can also be simple, since it operates on one-dimensional positive data. The classifier needs to work with small amounts of data, so it does not block anomaly detection. The classifier emits two values to aid the user: (1) anomaly grade, quantifying severity of the anomaly, and (2) confidence, quantifying the amount of data seen and RCF size.
Second, RCFs require training time to learn the initial distribution (i.e., the forest). An RCF requires hundreds of samples, which takes time to arrive at the Elasticsearch cluster. This prevents both interactive exploration of anomalies on current and past data (e.g., using queries), and delays the time-to-detection. In practice, users would define and turn on a detector after ingesting some data – we can leverage this to train an initial model. Further, to support interactive ad-hoc exploration, we need to a fast RCF construction primitive on data at rest.
System Design
Since the anomaly detection system builds on top of Elasticsearch, it should be very lightweight and highly elastic to changes in cluster state and resource availability. We leverage statistical multiplexing to use available resources on the cluster and have the system adapt to cluster state changes in real time, to keep resources intact for the user workload. Note that the algorithms themselves are very lightweight and have tight memory and compute requirements. This also ensures that we build the lowest cost anomaly detectors on the Elasticsearch cluster.
Feature Computation
The first step to anomaly detection is feature computation. The user defines features via the anomaly detection API or the Kibana anomaly detector interface. Each feature is mapped to an Elasticsearch query string. The system issues queries for each feature at the frequency specified by the user; we upper-bound the frequency to once a minute to contain query overheads. Queries also leverage the power statistical multiplexing, since they are distributed computations across all shards of the index. We also limit the set of aggregations that feature computations support, since feature samples are currently limited to one-dimensional numbers. The system aborts queries that take longer than a threshold and throttles queries if the latencies are high (the impact of this is lower confidence of detection; not detection itself).
Training and Inference
The next step is to schedule training and inference for anomaly detection. Since a random forest is an independent set of trees, this is a parallel execution on the cluster. An elected node on the cluster acts as the coordinator node for an anomaly detector. The coordinator schedules queries for feature computation; and schedules and manages partitions of the RCF on different nodes and the computation for the classifier (score-to-detection function). Changes in cluster membership trigger reassignments of the compute jobs. Each compute job periodically checkpoints its state (i.e., trees and classifier parameters) in an Elasticsearch index to handle job reassignments and for fault tolerance. The checkpoints eliminate the need to re-train trees and classifier for a new job assignment. Reassignments are also throttled when necessary.
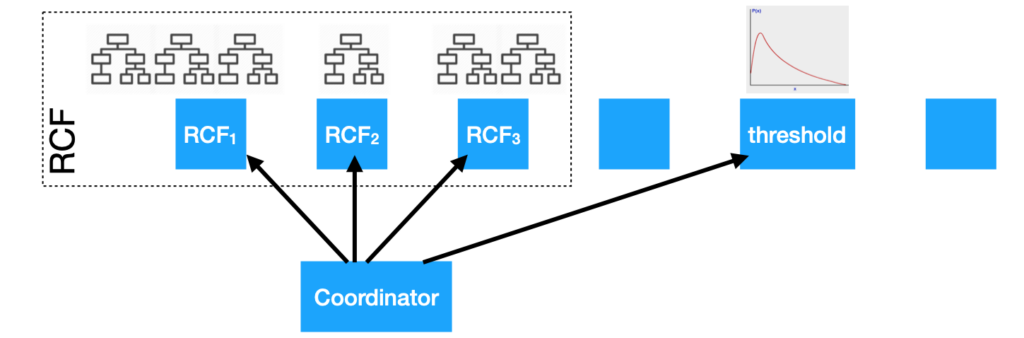
Orchestrating RCF and score classifier computation on Elasticsearch cluster.
Fault tolerance, Elasticity and Availability
The system is designed to be highly elastic. It adapts in real time to cluster membership changes (described above), and to changes in resource availability on the cluster nodes. Each node of the cluster adapts to heap availability on the JVM to size the number of trees on the RCF partition (there is also an upper bound on number of trees in a partition). A node-level circuit breaker also shuts down all RCF partitions on a node in extreme cases. Note that these actions only impact the confidence of the anomaly detections not the availability of anomaly detection service itself. When a detector temporarily aborts or skips query samples to adapt to resource availability drops, we use linear or nearest neighbor interpolation to fill sparse “holes” in feature samples (this has minimal impact on detection accuracy). The only case where a detector is unavailable is when all partitions are shut down or the threshold model is shut down; this is a case where the Elasticsearch cluster is under stress, and may be low on availability as well.
It is equally important to build monitoring primitives to allow the user to understand the detector output and availability. As mentioned above, the system exposes confidence and anomaly grade for each detection. In addition, the system should notify or record when there are missing data samples for periods of time, changes in compute job sizes, and the impact (if any) of anomaly detectors on Elasticsearch ingestion and query workloads.
Summary
In this blog post, we introduced the real time anomaly detection feature in Open Distro in Elasticsearch. It runs asynchronously during ingestion time, and has very low overhead, which makes it suitable to run within the cluster without impacting cluster performance. We covered the Random Cut Forest algorithm and the model partitioning and elasticity in the system, which makes anomaly detection highly available. We briefly touched upon support that we are introducing to enable interactive exploration of anomalies on live and offline data in Elasticsearch. We are excited for the future of real time anomaly detection for Elasticsearch and welcome you to come join in and contribute with us in building anomaly detection and machine learning capabilities in Open Distro for Elasticsearch.
References
- Fei Tony Liu, Kai Ming Ting, and Zhi-Hua Zhou. 2008. Isolation Forest. In Proceedings of the 2008 Eighth IEEE International Conference on Data Mining (ICDM ‘08)
- Sudipto Guha, Nina Mishra, Gourav Roy, and Okke Schrijvers. 2016. Robust random cut forest based anomaly detection on streams. In Proceedings of the 33rd International Conference on International Conference on Machine Learning (ICML’16)
- RANDOM_CUT_FOREST, Amazon Kinesis Data Analytics documentation
- What RCF Is and What It Does, Amazon Quicksight documentation
- Random Cut Forest (RCF) Algorithm, Amazon SageMaker Developer Guide
- Varun Chandola, Arindam Banerjee, and Vipin Kumar. 2009. Anomaly detection: A survey. ACM Computing Surveys,* 41, 3, Article 15 (July 2009), 58 pages