You're viewing version 2.14 of the OpenSearch documentation. This version is no longer maintained. For the latest version, see the current documentation. For information about OpenSearch version maintenance, see Release Schedule and Maintenance Policy.
Search pipelines
You can use search pipelines to build new or reuse existing result rerankers, query rewriters, and other components that operate on queries or results. Search pipelines make it easier for you to process search queries and search results within OpenSearch. Moving some of your application functionality into an OpenSearch search pipeline reduces the overall complexity of your application. As part of a search pipeline, you specify a list of processors that perform modular tasks. You can then easily add or reorder these processors to customize search results for your application.
Terminology
The following is a list of search pipeline terminology:
- Search request processor: A component that intercepts a search request (the query and the metadata passed in the request), performs an operation with or on the search request, and returns the search request.
- Search response processor: A component that intercepts a search response and search request (the query, results, and metadata passed in the request), performs an operation with or on the search response, and returns the search response.
- Search phase results processor: A component that runs between search phases at the coordinating node level. A search phase results processor intercepts the results retrieved from one search phase and transforms them before passing them to the next search phase.
- Processor: Either a search request processor or a search response processor.
- Search pipeline: An ordered list of processors that is integrated into OpenSearch. The pipeline intercepts a query, performs processing on the query, sends it to OpenSearch, intercepts the results, performs processing on the results, and returns them to the calling application, as shown in the following diagram.
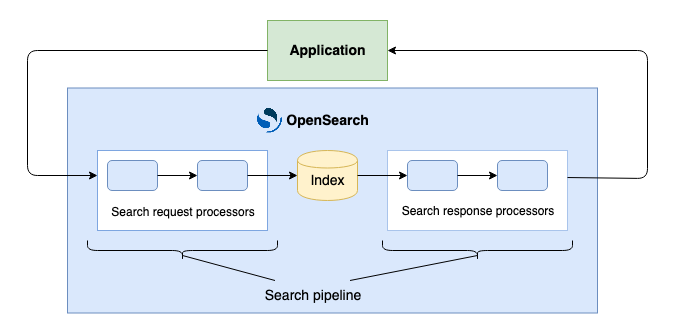
Both request and response processing for the pipeline are performed on the coordinator node, so there is no shard-level processing.
Processors
To learn more about available search processors, see Search processors.
Example
To create a search pipeline, send a request to the search pipeline endpoint specifying an ordered list of processors, which will be applied sequentially:
PUT /_search/pipeline/my_pipeline
{
"request_processors": [
{
"filter_query" : {
"tag" : "tag1",
"description" : "This processor is going to restrict to publicly visible documents",
"query" : {
"term": {
"visibility": "public"
}
}
}
}
],
"response_processors": [
{
"rename_field": {
"field": "message",
"target_field": "notification"
}
}
]
}
For more information about creating and updating a search pipeline, see Creating a search pipeline.
To use a pipeline with a query, specify the pipeline name in the search_pipeline query parameter:
GET /my_index/_search?search_pipeline=my_pipeline
Alternatively, you can use a temporary pipeline with a request or set a default pipeline for an index. To learn more, see Using a search pipeline.
To learn about retrieving details for an existing search pipeline, see Retrieving search pipelines.
Search pipeline metrics
For information about retrieving search pipeline statistics, see Search pipeline metrics.