Target throughput
Target throughput is key to understanding the OpenSearch Benchmark definition of latency. Target throughput is the rate at which OpenSearch Benchmark issues requests, assuming that responses will be returned instantaneously. target-throughput is a common workload parameter that can be set for each test and is measured in operations per second.
OpenSearch Benchmark has two testing modes, both of which are related to throughput, latency, and service time:
- Benchmarking mode: Latency is measured in the same way as service time.
- Throughput-throttled mode: Latency is measured as service time plus the time that a request spends waiting in the queue.
Benchmarking mode
When you do not specify a target-throughput, OpenSearch Benchmark latency tests are performed in benchmarking mode. In this mode, the OpenSearch client sends requests to the OpenSearch cluster as fast as possible. After the cluster receives a response from the previous request, OpenSearch Benchmark immediately sends the next request to the OpenSearch client. In this testing mode, latency is identical to service time.
Throughput-throttled mode
Throughput measures the rate at which OpenSearch Benchmark issues requests, assuming that responses will be returned instantaneously. However, users can set a target-throughput, which is a common workload parameter that can be set for each test and is measured in operations per second.
OpenSearch Benchmark issues one request at a time for a single-client thread, which is specified as search-clients in the workload parameters. If target-throughput is set to 0, then OpenSearch Benchmark issues a request immediately after it receives the response from the previous request. If the target-throughput is not set to 0, then OpenSearch Benchmark issues the next request in accordance with the target-throughput, assuming that responses are returned instantaneously.
When you want to simulate the type of traffic you might encounter when deploying a production cluster, set the target-throughput in your benchmark test to match the number of requests you estimate that the production cluster might receive. The following examples show how the target-throughput setting affects the latency measurement.
Example A
The following diagrams illustrate how latency is calculated with an expected request response time of 200 ms and the following settings:
search-clientsis set to1.target-throughputis set to1operation per second.

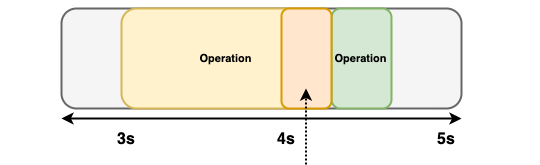
When a request takes longer than 200 ms, such as when a request takes 1110 ms instead of 400 ms, OpenSearch Benchmark sends the next request that was supposed to occur at 4.00 s based on the target-throughput of 4.10 s. All requests subsequent to the 4.10 s request attempt to re-synchronize with the target-throughput setting, as shown in the following image:

When measuring the overall latency, OpenSearch Benchmark includes all performed requests. All requests have a latency of 200 ms, except for the following two requests:
- The request that lasted 1100 ms.
- The subsequent request which should have started at 4.00 s. This request was delayed by 100 ms, denoted by the orange-colored area in the following diagram, and had a response time of 200 ms. When calculating the latency for this request, OpenSearch Benchmark accounts for the delayed start time and combines it with the response time. The latency for this request is 300 ms.
Example B
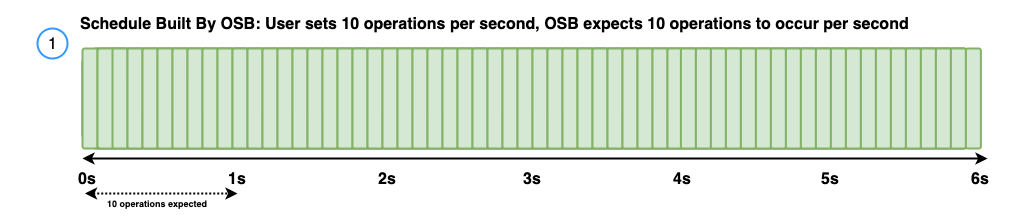
In this example, OpenSearch Benchmark assumes a latency of 200 ms and uses the following latency settings:
search_clientsis set to1.target-throughputis set to10operations per second.
The following diagram shows the schedule built by OpenSearch Benchmark with the expected response times.
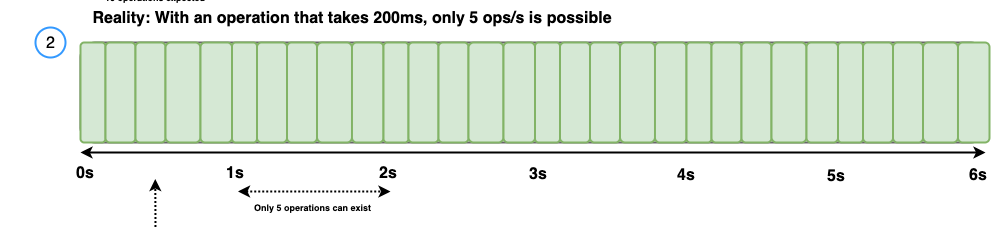
However, if it is assumed that all responses will have a latency of 200 ms, then 10 operations per second won’t be possible. Therefore, the highest throughput that OpenSearch Benchmark can reach is 5 operations per second, as shown in the following diagram.
OpenSearch Benchmark does not account for this limitation and continues to try to achieve the target-throughput of 10 operations per second. Because of this, delays for each request begin to cascade, as illustrated in the following diagram.
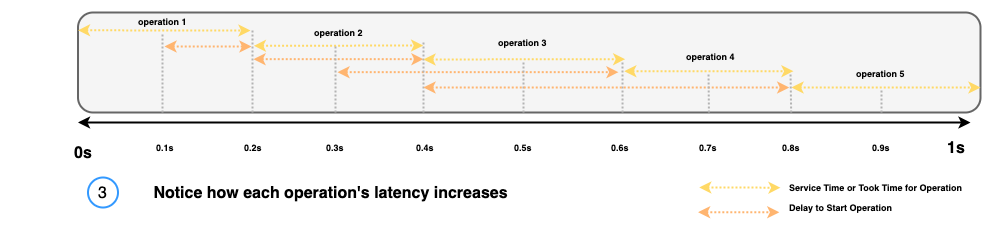
By combining the service time and the delay for each operation, the following latency measurements are provided for each operation:
- 200 ms for operation 1
- 300 ms for operation 2
- 400 ms for operation 3
- 500 ms for operation 4
- 600 ms for operation 5
This latency cascade continues, increasing latency by 100 ms for each subsequent request.
Recommendation
As shown in the preceding examples, you should be aware of each task’s average service time and should provide a target-throughput that accounts for the service time. OpenSearch Benchmark latency is calculated based on the target-throughput set by the user; therefore, latency could be redefined as throughput-based latency.