You're viewing version 2.8 of the OpenSearch documentation. This version is no longer maintained. For the latest version, see the current documentation. For information about OpenSearch version maintenance, see Release Schedule and Maintenance Policy.
Search pipelines
This is an experimental feature and is not recommended for use in a production environment. For updates on the progress of the feature or if you want to leave feedback, join the discussion in the OpenSearch forum.
You can use search pipelines to build new or reuse existing result rerankers, query rewriters, and other components that operate on queries or results. Search pipelines make it easier for you to process search queries and search results within OpenSearch. Moving some of your application functionality into an OpenSearch search pipeline reduces the overall complexity of your application. As part of a search pipeline, you specify a list of processors that perform modular tasks. You can then easily add or reorder these processors to customize search results for your application.
Enabling search pipelines
Search pipeline functionality is disabled by default. To enable it, edit the configuration in opensearch.yml and then restart your cluster:
- Navigate to the OpenSearch config directory.
- Open the
opensearch.ymlconfiguration file. - Add
opensearch.experimental.feature.search_pipeline.enabled: trueand save the configuration file. - Restart your cluster.
Terminology
The following is a list of search pipeline terminology:
- Search request processor: A component that takes a search request (the query and the metadata passed in the request), performs an operation with or on the search request, and returns a search request.
- Search response processor: A component that takes a search response and search request (the query, results, and metadata passed in the request), performs an operation with or on the search response, and returns a search response.
- Processor: Either a search request processor or a search response processor.
- Search pipeline: An ordered list of processors that is integrated into OpenSearch. The pipeline intercepts a query, performs processing on the query, sends it to OpenSearch, intercepts the results, performs processing on the results, and returns them to the calling application, as shown in the following diagram.
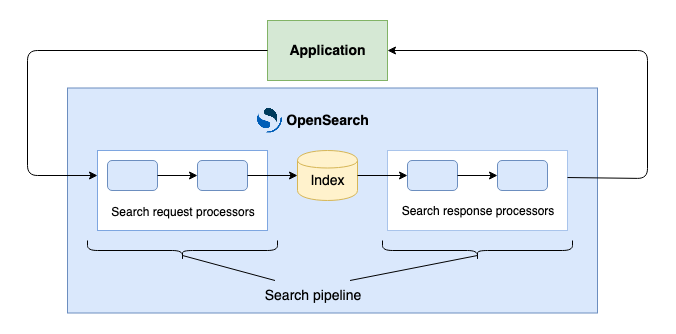
Both request and response processing for the pipeline are performed on the coordinator node, so there is no shard-level processing.
Search request processors
OpenSearch supports the following search request processors:
script: Adds a script that is run on newly indexed documents.filter_query: Adds a filtering query that is used to filter requests.
Search response processors
OpenSearch supports the following search response processors:
rename_field: Renames an existing field.
Viewing available processor types
You can use the Nodes Search Pipelines API to view the available processor types:
GET /_nodes/search_pipelines
The response contains the search_pipelines object that lists the available request and response processors:
Response
{
"_nodes" : {
"total" : 1,
"successful" : 1,
"failed" : 0
},
"cluster_name" : "runTask",
"nodes" : {
"36FHvCwHT6Srbm2ZniEPhA" : {
"name" : "runTask-0",
"transport_address" : "127.0.0.1:9300",
"host" : "127.0.0.1",
"ip" : "127.0.0.1",
"version" : "3.0.0",
"build_type" : "tar",
"build_hash" : "unknown",
"roles" : [
"cluster_manager",
"data",
"ingest",
"remote_cluster_client"
],
"attributes" : {
"testattr" : "test",
"shard_indexing_pressure_enabled" : "true"
},
"search_pipelines" : {
"request_processors" : [
{
"type" : "filter_query"
},
{
"type" : "script"
}
],
"response_processors" : [
{
"type" : "rename_field"
}
]
}
}
}
}
In addition to the processors provided by OpenSearch, additional processors may be provided by plugins.
Creating a search pipeline
Search pipelines are stored in the cluster state. To create a search pipeline, you must configure an ordered list of processors in your OpenSearch cluster. You can have more than one processor of the same type in the pipeline. Each processor has a tag identifier that distinguishes it from the others. Tagging a specific processor can be helpful for debugging error messages, especially if you add multiple processors of the same type.
Example request
The following request creates a search pipeline with a filter_query request processor that uses a term query to return only public messages:
PUT /_search/pipeline/my_pipeline
{
"request_processors": [
{
"filter_query" : {
"tag" : "tag1",
"description" : "This processor is going to restrict to publicly visible documents",
"query" : {
"term": {
"visibility": "public"
}
}
}
}
]
}
Retrieving search pipelines
To retrieve the details of an existing search pipeline, use the Search Pipeline API.
To view all search pipelines, use the following request:
GET /_search/pipeline
The response contains the pipeline that you set up in the previous section:
Response
{
"my_pipeline" : {
"request_processors" : [
{
"filter_query" : {
"tag" : "tag1",
"description" : "This processor is going to restrict to publicly visible documents",
"query" : {
"term" : {
"visibility" : "public"
}
}
}
}
]
}
}
To view a particular pipeline, specify the pipeline name as a path parameter:
GET /_search/pipeline/my_pipeline
You can also use wildcard patterns to view a subset of pipelines, for example:
GET /_search/pipeline/my*
Using a search pipeline
To search with a pipeline, specify the pipeline name in the search_pipeline query parameter:
GET /my_index/_search?search_pipeline=my_pipeline
For a complete example of using a search pipeline with a filter_query processor, see filter_query processor example.
Default search pipeline
For convenience, you can set a default search pipeline for an index. Once your index has a default pipeline, you don’t need to specify the search_pipeline query parameter in every search request.
Setting a default search pipeline for an index
To set a default search pipeline for an index, specify the index.search.default_pipeline in the index’s settings:
PUT /my_index/_settings
{
"index.search.default_pipeline" : "my_pipeline"
}
After setting the default pipeline for my_index, you can try the same search for all documents:
GET /my_index/_search
The response contains only the public document, indicating that the pipeline was applied by default:
Response
{
"took" : 19,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 0.0,
"hits" : [
{
"_index" : "my_index",
"_id" : "1",
"_score" : 0.0,
"_source" : {
"message" : "This is a public message",
"visibility" : "public"
}
}
]
}
}
Disabling the default pipeline for a request
If you want to run a search request without applying the default pipeline, you can set the search_pipeline query parameter to _none:
GET /my_index/_search?search_pipeline=_none
Removing the default pipeline
To remove the default pipeline from an index, set it to null or _none:
PUT /my_index/_settings
{
"index.search.default_pipeline" : null
}
PUT /my_index/_settings
{
"index.search.default_pipeline" : "_none"
}
Updating a search pipeline
To update a search pipeline dynamically, replace the search pipeline using the Search Pipeline API.
Example request
The following request upserts my_pipeline by adding a filter_query request processor and a rename_field response processor:
PUT /_search/pipeline/my_pipeline
{
"request_processors": [
{
"filter_query": {
"tag": "tag1",
"description": "This processor returns only publicly visible documents",
"query": {
"term": {
"visibility": "public"
}
}
}
}
],
"response_processors": [
{
"rename_field": {
"field": "message",
"target_field": "notification"
}
}
]
}
Search pipeline versions
When creating your pipeline, you can specify a version for it in the version parameter:
PUT _search/pipeline/my_pipeline
{
"version": 1234,
"request_processors": [
{
"script": {
"source": """
if (ctx._source['size'] > 100) {
ctx._source['explain'] = false;
}
"""
}
}
]
}
The version is provided in all subsequent responses to get pipeline requests:
GET _search/pipeline/my_pipeline
The response contains the pipeline version:
Response
{
"my_pipeline": {
"version": 1234,
"request_processors": [
{
"script": {
"source": """
if (ctx._source['size'] > 100) {
ctx._source['explain'] = false;
}
"""
}
}
]
}
}