
As we witness the evolution of ML models, like large language models (LLMs), imagine if they possessed a new dimension – the ability to comprehend images. Similar to the game-changing impact of LLMs in chatbots and text data, this new capability has the potential to revolutionize businesses by allowing ML models to decipher and categorize extensive image collections within enterprise IT systems.
What are vector embeddings?
One of the most compelling applications of deep learning models is the creation of an embedding space. When generating embeddings, the model maps an entity (image, text, audio, or video) to a multi-dimensional vector. This vector captures the semantic meaning and visual representation of the entity. Thus, an image embedding model maps an image into a multi-dimensional vector that you can use to perform an image similarity search. In this search, you provide an image and search for other visually and contextually related images. For example, in the following illustration, both dog images map to vectors that are close to each other but far from the vectors that represent a person or a car image.
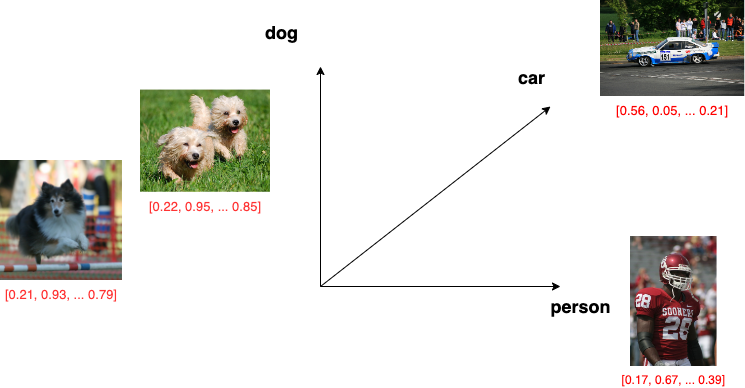
How do multimodal models generate embeddings?
Let’s look closely at how multimodal models generate embeddings. Consider one of the first multimodal models: CLIP from OpenAI. This model has a two-tower architecture that includes an image embedding model (usually referred to as image encoder) and a text embedding model (referred to as text encoder). CLIP trains on image-text pairs, where each image has a corresponding text caption. The image and text encoders convert each image and text into separate embeddings. A similarity score is then calculated between the text and image embeddings. The goal of the training is to maximize the similarity score of the same image-text pairs and minimize the score of different pairs.
During model training, the image and text embeddings are mapped onto a joint embedding space. In this space, similar images and text descriptions are close to each other, while dissimilar images and descriptions are farther away. Thus, in the eyes of the model, there is no fundamental difference between images and descriptions.
Three types of multimodal search
The joint embedding space enables the following pivotal search functionalities:
- Text-to-image search, which retrieves images based on text queries.
- Image-to-text search, which retrieves textual content based on visual queries.
- Image-to-image search, which retrieves images that are most similar to a provided image.
You can also use combinations of these search methods. For example, you can augment your image-to-image search with text and make it (image+text)-to-image. Let’s illustrate this with an example.
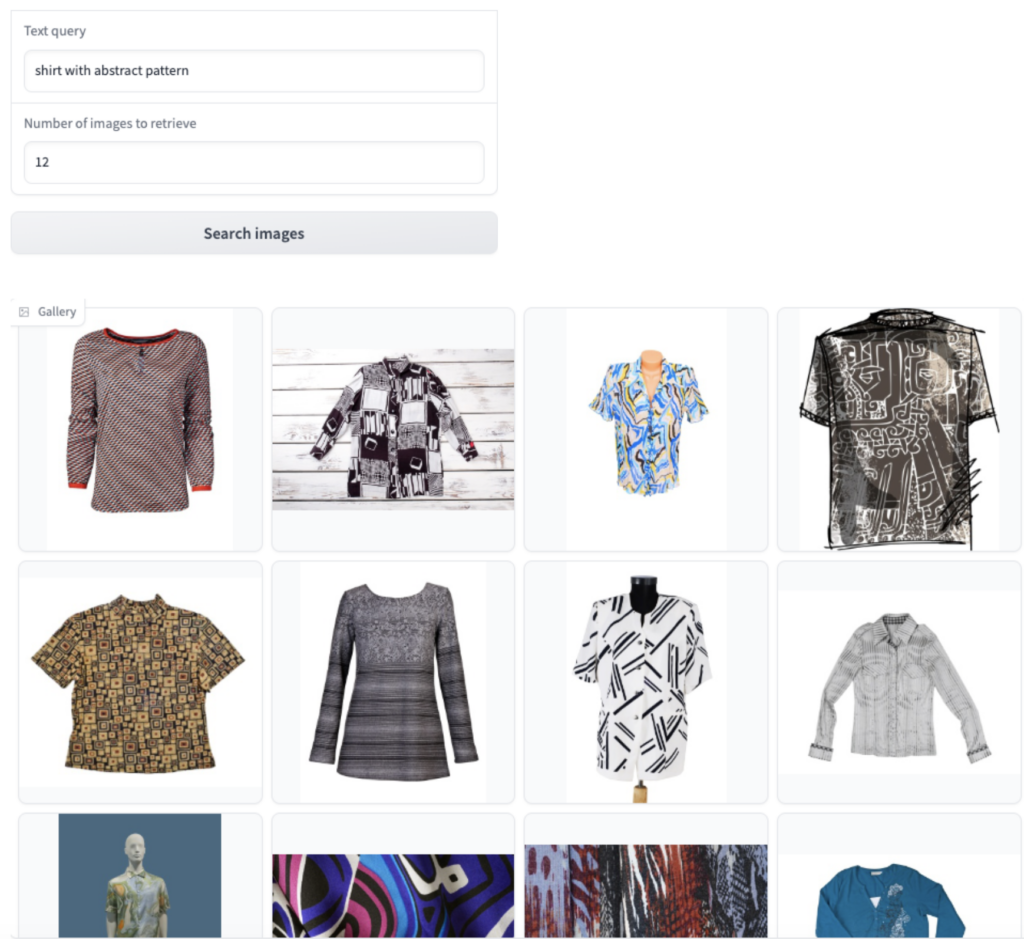
First attempt: Text-to-image search
Let’s say you’re looking for a certain type of clothing. You start with a text query “shirt with abstract pattern,” and the model returns results from the catalog of available products using text-to-image search capabilities. It understands that “abstract” is a description of a pattern and correctly identifies such patterns, as shown in the following image.
Narrowing down the results: Image-to-image search
A query such as the previous one can return results that are too diverse. This is mainly because the query itself is not specific enough in terms of many characteristics, such as the exact color theme. The easiest way to narrow down the results to the shirt you have in mind is to pick one of the results and do an image-to-image search. The model will then return products that have a style similar to the selected product, as shown in the following image.
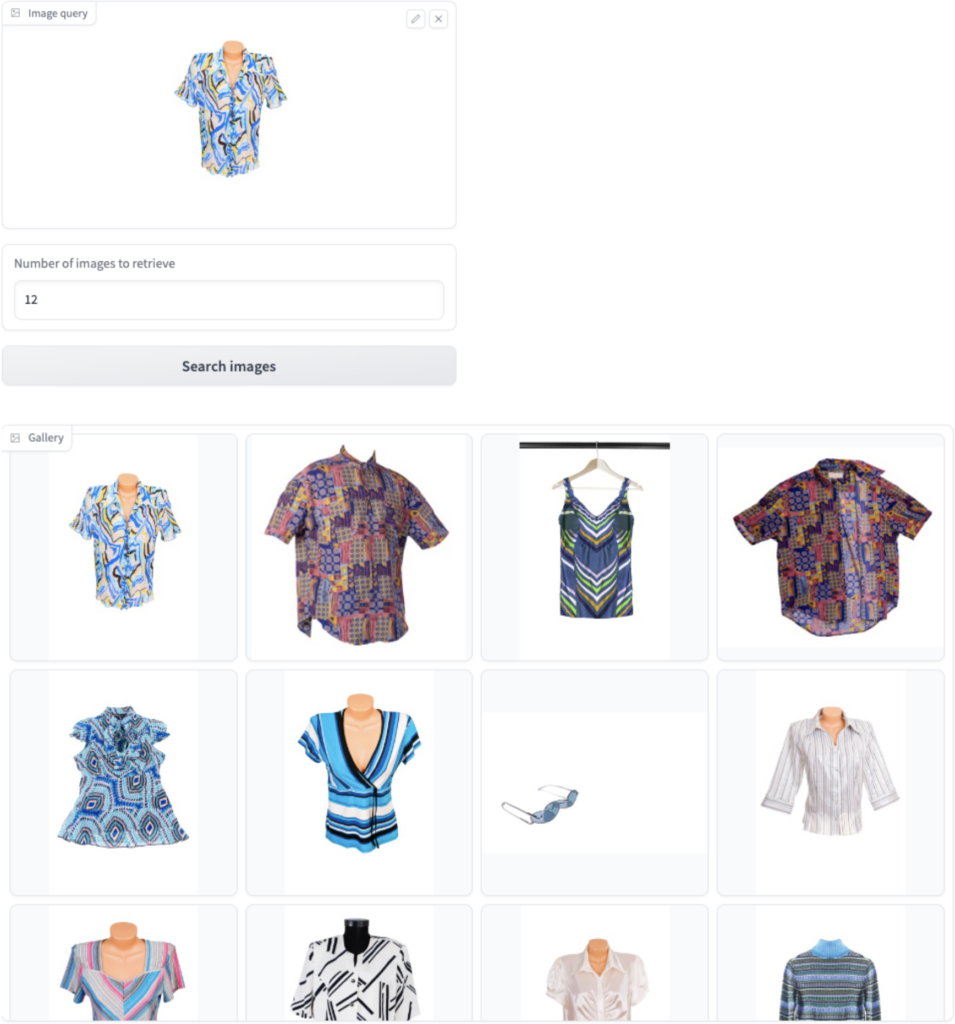
The image-to-image search returns results that are much more specific. In this example, the results mostly contain short-sleeved tops in shades of blue.
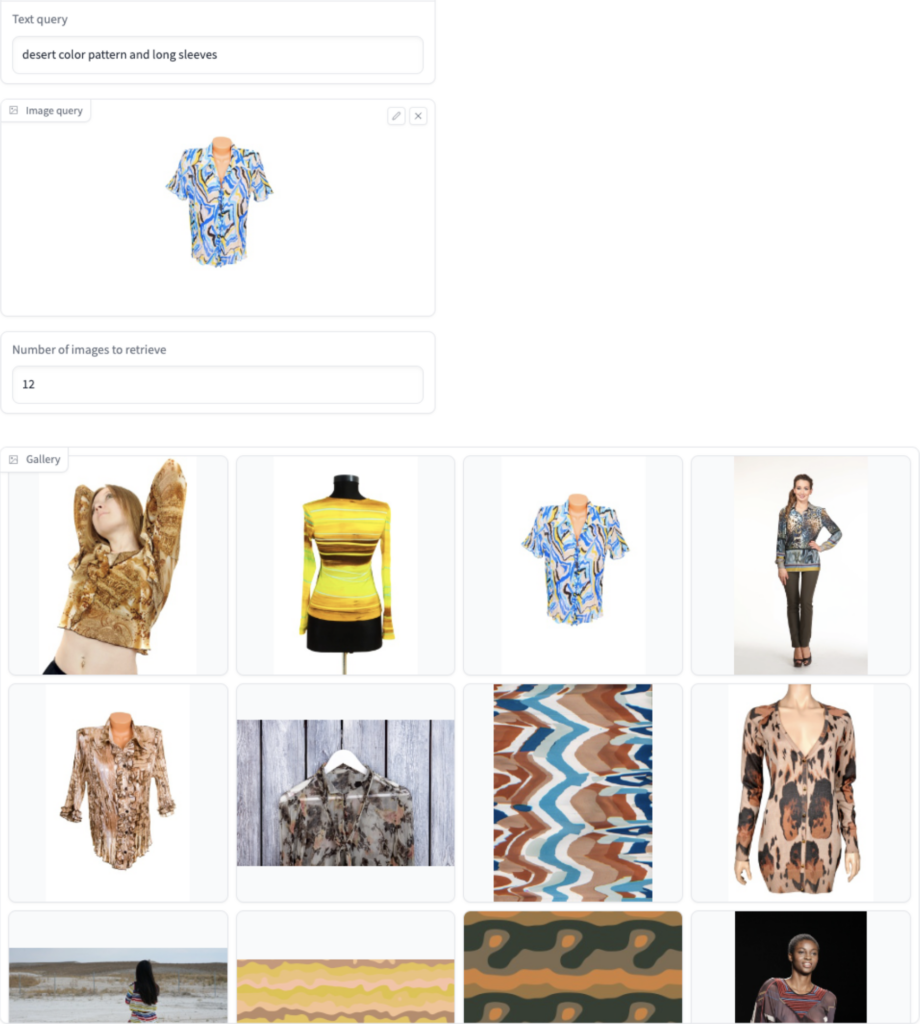
Combining the two search types: (Image+text)-to-image search
As a final touch, you may want to narrow the results down even further by combining an image and text search. Thus, you select an image whose style you want to match and augment the image search with a text query that looks for “desert color pattern and long sleeves.” The following image shows the results of such a combined query.
How is combined search traditionally implemented?
Today, the conventional implementation of a combined search starts with a person scanning the image and enriching it with metadata in the form of structured text. Subsequently the search process operates in a text-to-text manner, relying on queries and manually inputted metadata text fields.
However, this approach comes with several drawbacks. Metadata may lack certain characteristics because of human oversight or inaccuracies during the manual input process. If an image undergoes updates, the entire manual process needs to be repeated. Additionally, the hosting system managing the metadata requires ongoing maintenance.
With a multimodal model, such manual process is not necessary. The model can perform multimodal search without any prior explicit training—a feat accomplished through zero-shot learning.
The new multimodal search in OpenSearch
In the past, OpenSearch users built multimodal search applications by indexing vector embeddings created by models like CLIP into an OpenSearch k-NN index. We saw an opportunity to simplify the builder experience by creating a simpler query interface. With the new interface, you can query using text or image instead of writing vector-based k-NN queries. Previously, you had to set up and run pipelines that integrate multimodal models and translate text and image inputs into k-NN queries. The new interface eliminates the need for building and maintaining such intermediate layer.
We first delivered the new interface that provides semantic search capability in OpenSearch 2.9, as part of neural search. Now, the neural search experience includes text- and image-based multimodal search. The multimodal pipelines that we support on-cluster are powered by AI connectors to multimodal model providers. To facilitate multimodal search, we’ve provided a connector for the Titan Multimodal Embeddings model on Amazon Bedrock.
Our initial release was designed around the Amazon Bedrock Multimodal Embeddings API. Because of this, you’ll need to adhere to certain design constraints when using embeddings generated by other multimodal embedding providers. For instance, your multimodal API must be designed for text and image. Our system will pass the image data as Base64 encoded binary. Your API should also be able to generate a single vector embedding, which can be queried by embeddings generated for both text and image modalities.
We realized that some multimodal models can’t operate within these constraints. However, we have broader plans to rework our framework, removing the current limitations and providing more generic custom model integration support. We revealed this plan in a recent blog post. Nonetheless, we opted to deliver multi-modal support for neural search sooner because we believe our users have a lot to gain now instead of waiting later this year. ß Our product vision and strategy continues to be open. To make it easy for AI technology providers to integrate with OpenSearch, we have created a machine learning extensibility framework. Our choice to start with the Amazon Bedrock Titan Multimodal Embeddings support was intended to deliver timely incremental value for OpenSearch users.
Introducing the Titan Multimodal Embeddings Model
At re:Invent 2023, AWS introduced a new Titan model—Titan Multimodal Embeddings, which integrates with OpenSearch multimodal search. Developed in house from the ground up, the Titan Multimodal Embeddings model provides state-of-the-art multimodal retrieval performance out of the box with 1024-dimensional embeddings for image-to-text, text-to-image and (image+text)-to-text use cases. Titan also supports 384-dimensional and 256-dimensional embedding sizes. When combined with OpenSearch, the smaller embeddings can provide faster retrieval with a small decrease in accuracy.
Similar to other multimodal embedding models, the Titan model has a two-tower architecture, which includes an image encoder and a text encoder. The Titan multimodal model is trained on image-text pairs, where each image has a corresponding text caption (made of up to 128 tokens). Therefore, the model can map images and text onto a joint embedding space, as shown in the following image.
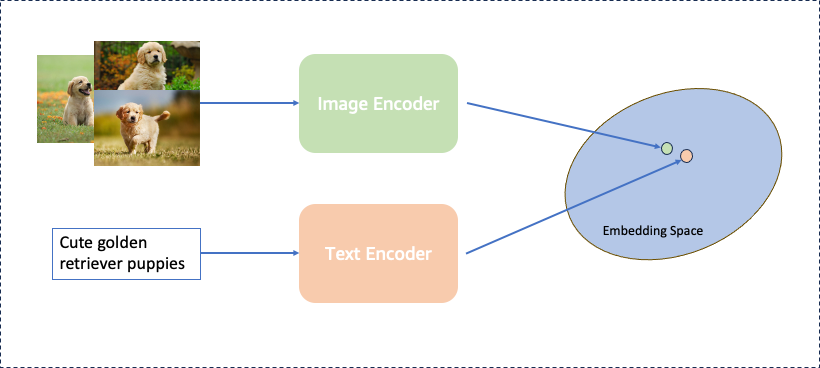
One key advantage of the Titan Multimodal Embeddings model over existing models such as CLIP is the quality of training data. Multimodal models use a large volume of image-text pairs for training. A common problem for such a large dataset is the noise in the data, which mainly comes from a mismatch between the text and image. For example, the image of an Amazon marketplace product might not exactly match the description provided by the seller. For multimodal models, this noise leads to a worse performance. In contrast, to bootstrap the training, the Titan Multimodal Embeddings model uses carefully curated, strongly aligned image-text pairs, greatly reducing the noise in training data. Compared to state-of-the-art models, the Titan Multimodal Embeddings model achieves better, faster performance.
How to use multimodal search in OpenSearch
To try multimodal search in OpenSearch, you need to ingest data and obtain text and image embeddings from a multimodal model. The process consists of two major steps:
- Setting up a model. For steps to set up a model that is hosted on a third-party platform, see Connecting to externally hosted models.
- Using a model for search. For steps to set up multimodal search, see Multimodal search.
Setting up a model
First, select a multimodal model. You’ll need to set up a connector to the model. For information about creating connectors, see Connectors. OpenSearch provides connectors to several models, such as Cohere models, OpenAI ChatGPT, and the Amazon Titan Multimodal Embeddings Model. For more information, see Supported connectors.
Using a model for search
Next, create an ingest pipeline with a text_image_embedding ingest processor in order to obtain vector embeddings:
PUT /_ingest/pipeline/nlp-pipeline-text-image
{
"description": "An example of ingest pipeline for text and image embeddings",
"processors": [
{
"text_image_embedding": {
"model_id": "1234567890",
"embedding": "vector_embedding",
"field_map": {
"image": "image_field",
"text": "text_field"
}
}
}
]
}
Provide the model_id of the multimodal model created in the previous step.
OpenSearch creates a single vector embedding that combines image and text information.
To run multimodal search, use a neural query:
GET /my-index/_search
{
"query": {
"neural": {
"vector_embedding": {
"query_text": "table lamp",
"query_image": "base64_for_image_abcdef12345678",
"model_id": "1234567890",
"k": 100
}
}
}
}
You can combine text, image, and text-and-image embeddings. For instance, you can create embeddings only from the image and send both text and image as part of the search request. You can still use only text or only image to do a search even if embeddings for your data were created using both text and image information.
Multimodal search has been released in OpenSearch 2.11. For more information and examples of multimodal search, see Multimodal search.
Best practices for using the Titan Multimodal Embeddings model
The Titan Multimodal Embeddings model generates embeddings for three types of input:
- Text (as a string)
- Image (as a base64 string)
- Image combined with text
You can store the generated embeddings in a database or use them in a query to search the database.
From simple to complex queries: Titan multimodal embeddings
With the images indexed, you can use any text queries to retrieve relevant images in the database, for example:
- Simple queries containing one object with different attributes:
cat,dog,red-colored hat,winter clothes. - Composite queries containing multiple objects:
a white cat on a leather sofa,two people with red umbrellas. - Queries in the form of complete sentences:
Two people are walking a dog on a Paris street.
Note that the text encoder in the Titan multimodal embeddings model is not a generative large language model (LLM). It cannot reason or deduce a conclusion from a query. For example, using Titan Multimodal Embeddings to search for clothes similar to Princess Diana’s fashion style in the 80s will be less effective. To overcome this limitation, you can potentially use an LLM to decompose the query into simple terms such as Floral shirts, Yellow overalls, Neck scarves, Dusters, Flowy skirts, Collared shirts, Sweaters. After doing so, you can use the Titan multimodal model effectively to retrieve similar clothes.
Circumventing the text token length limitations
Titan Multimodal Embeddings is mainly intended for searching image databases using text, image or image+text queries. Although the model has the best-in-class support for text length of up to 128 tokens, it is not intended for use as a pure text embedding model. If your use case is mainly to index long paragraphs or documents, a model with only text embeddings is a more appropriate choice.
For some use cases, text queries can contain more than 128 tokens. By default, the Titan multimodal model truncates the text to suitable length, then outputs the embeddings for the truncated text. This simple solution can lead to suboptimal performance. If your queries frequently contain long text, we suggest two possible solutions to circumvent the token limitation:
- Use text preprocessing, such as stemming and lemmatization, with the help of tools such as Natural Language Toolkit (NLTK).
- Use LLM summarization of a text query.
Fine-tuning the model on individual use cases
To evaluate the model performance, similarly to evaluating other retrieval systems, you can test the model on a golden set of queries (the most representative set of queries for your retrieval use cases). Based on the relevance of the retrieved results, you can determine whether Titan Multimodal Embeddings satisfies the accuracy requirements. If you are not satisfied with the out-of-the-box performance of the model on your use cases, you can further fine-tune Titan Multimodal Embeddings.
Using as few as 1000 image-text pairs, you can significantly improve the model’s performance on rare domains, such as medical or aerial imagery. As we mentioned previously, the alignment between image and text in the training data will impact fine-tuning performance. Therefore, before fine-tuning, it is crucial to ensure that the image-text pairs accurately reflect the same semantic content.
To collect the best training data, you can first start from a golden set of queries. Using each query, search for the best matching images in the database, which may or may not be part of the top results retrieved by Titan. The image and query represents an image-text pair that you can input into Titan’s fine-tuning API in order to tune the model automatically or with specified hyperparameters. You can then evaluate the performance of the fine-tuned model to ensure it satisfies your accuracy requirements.
Fine-tuning the Titan model does not change the image embeddings. If you already built your image database, you can deploy the fine-tuned model directly on the existing database, without reindexing the images, leading to better performance.
What’s next
There are many ways in which we can further improve multimodal semantic search:
- Add more content types that can be used to create embeddings: Adding content types such as video or audio can enrich search experiences and automate manual creation of metadata in various domains.
- Get image content from remote storage: In addition to exact base64-encoded image, you’ll be able to provide a URL so that OpenSearch can download the image content and encode it in real time. Doing so can save local disk space in case images are already stored in a remote system.
- Use multiple fields and embeddings for data ingestion: In the current approach, we can only support one pair of text and image fields. To process multiple pairs, you must set up a chain of multiple ingest processors. As a workflow improvement, we can make the processor support multiple text/image field pairs.
- Make model fields configurable: During multimodal search, you’ll be able to change the model on the fly by sending a request to OpenSearch instead of fixing the model in the beginning of search.
References
For more information, see the following documentation:
- Multimodal search https://opensearch.org/docs/latest/search-plugins/neural-multimodal-search/
- Connecting to remote models https://opensearch.org/docs/latest/ml-commons-plugin/extensibility/index/
- Using and building AI connectors https://community.aws/content/2ZUiRDEKnIg0PiwPevVTaJ7B9qg/introduction-to-opensearch-models


