

TLDR: Zero-result pages drain e-commerce revenue, and lexical query relaxing strategies like synonyms, fuzziness, and filter relaxation only go so far. Vector search in OpenSearch acts as a semantic safety net, retrieving relevant products when exact keyword matches fail. Fine-tuned models trained on real navigation data bridge the vocabulary gap. Scaling this for sub-100 ms response times requires ANN algorithms, deterministic routing via the preference parameter (which cut IOPS by 50% in production), native quantization, and recall-recovery techniques like ADC and Random Rotation. |
The limits of lexical search and query relaxing strategies
Lexical search relies on keywords and requires near-exact matches.
While it is inexpensive in terms of infrastructure, it lacks context and demands constant, advanced configuration (synonyms, stemming, lemmatization) to compensate for language variations.
When a user’s query diverges even slightly from the exact terms indexed in the catalog, whether through a complex phrase or a missing synonym, the engine finds nothing, resulting in a dead end.
To reduce the number of zero-result pages, “query relaxing” strategies are applied to make the search engine less restrictive:
- Filter Relaxation: Temporarily removing filters (such as brand or price) when a strict filter threatens to eliminate all results.
- Synonyms: Using synonym groups within OpenSearch (including industry-specific equivalents like “trousers” → “jeans” or normalized forms like “TV” → “Television”) to broaden the search.
- Fuzziness: Configuring automatic fuzziness based on the Levenshtein distance to handle typos and spelling mistakes. By using OpenSearch’s fuzziness: “AUTO”, you allow character permutations, additions, or deletions (up to two for words of six characters or more).
- Mandatory Terms: Configuring minimum_should_match (for example, to 2<70%) to ignore certain secondary words that are too limiting, thereby widening the net.
Semantic search as query relaxing
Despite the effectiveness of query relaxing, a small percentage of searches still yield zero results. With the rise of chatbots and natural language queries (e.g., “Quick meal”, “TV for Netflix”), it has become imperative to adopt a solution that understands semantics and user intent.
Vector search acts as a semantic safety net, retrieving relevant products for queries that lack a direct lexical match. OpenSearch facilitates this beautifully with its native k-NN plugin.
So how does it work in practice?
Instead of looking for matching letters, vector search looks for matching meanings. It uses machine learning models to translate both your product catalog and the user’s search query into dense numerical arrays called embeddings. Products with similar concepts end up close to each other in a mathematical space.
When a lexical search fails to find an exact word match for “Quick meal,” the system triggers the semantic fallback.
OpenSearch calculates the distance between the query’s vector and the products’ vectors using the k-Nearest Neighbors algorithm.
It retrieves the products located closest to the query in that mathematical space, such as instant noodles or microwaveable dishes, effortlessly bridging the vocabulary gap.
Optimization challenges: model fine-tuning
For a model to truly understand the specifics of e-commerce products, a generic model is not enough; fine-tuning is required.
In our case, the process involved training the model on millions of distinct [keyword, product] pairs collected from a year’s worth of navigation data.
Efficiency is further boosted by data augmentation, which includes:
- Duplicating entries with existing synonyms (e.g., “Kleenex” becomes “paper towel”).
- Intentionally creating spelling mistakes to make the model more robust.
- Using AI to generate potential keywords for a product, including translations or colloquial terms (e.g., “spud” for “potato”).
Once the model is ready, the indexing of product vectors into OpenSearch is achieved using highly relevant attributes like the Name, Category, and Brand.
Scaling for the High-Traffic E-commerce
At Adelean, our golden rule for e-commerce search is strict: response times must stay under 100 ms—often while operating with limited infrastructure resources.. While vector search is incredibly powerful for relevance, achieving this level of performance at scale is notoriously complicated
To keep latencies low and costs under control, these strategies are essential:
Choosing ANN over brute force
By default, an “exact” k-NN search calculates the distance between the query vector and every single document in your index. While providing exact distance calculations, this complexity is a performance killer for e-commerce catalogs with millions of products.
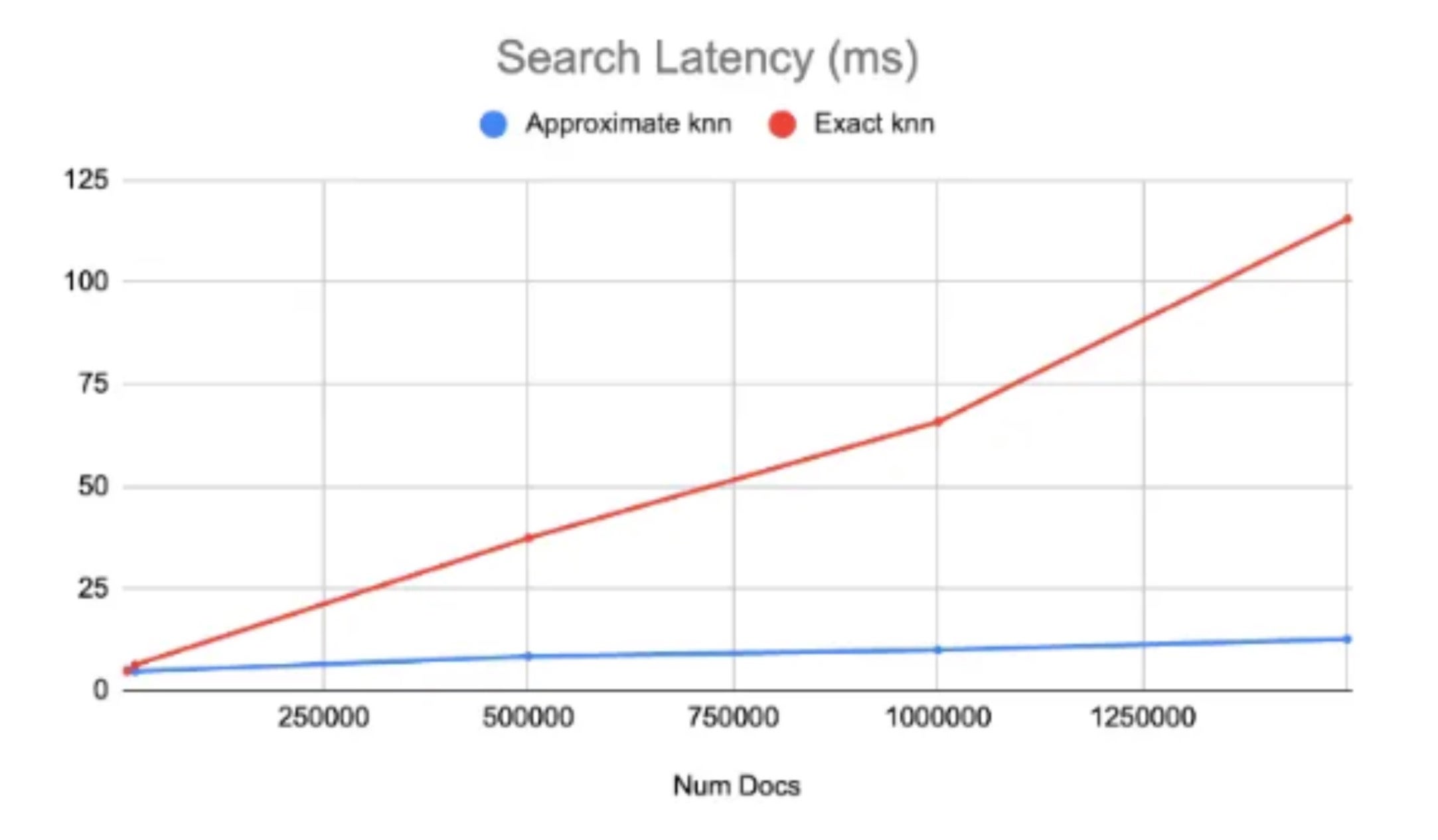
For production, it is essential to use Approximate Nearest Neighbor (ANN) algorithms, such as HNSW (Hierarchical Navigable Small World).
ANN trades a negligible amount of precision for a massive leap in speed, allowing OpenSearch to traverse a graph-based index to find matches in milliseconds rather than seconds.
Excluding _source
Because data is stored both for retrieval (_source) and for ANN search (the HNSW Index), excluding the heavy vector fields from the _source reduces disk space usage and unnecessary reads. This drastically optimizes I/O operations and network transfers.
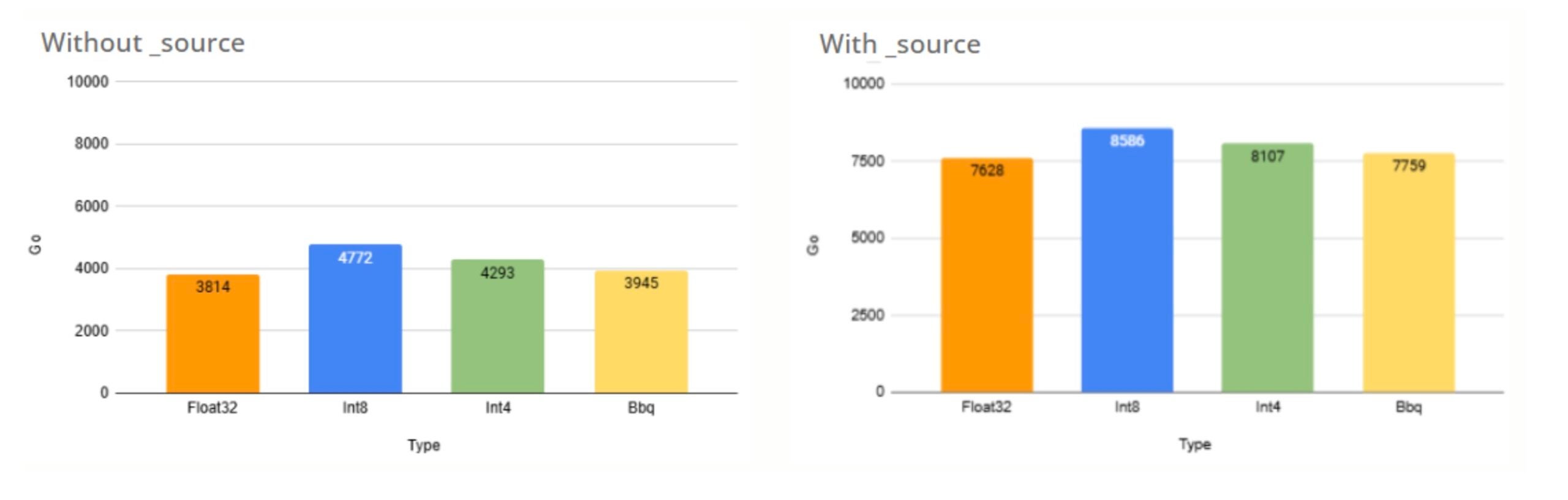
Note that starting from OpenSearch version 3.0, this optimization is built-in: the _source for vectors is automatically disabled and derived_source is used instead. This intelligent fallback allows for dynamic retrieval from the internal format only when explicitly needed (e.g., during a reindex), completely eliminating the massive storage overhead without losing flexibility.
Cache management via preference
By default, OpenSearch distributes search queries across replica shards using a round-robin approach to balance CPU load. However, with vector search, the CPU is rarely your biggest problem—RAM is.
On cost-constrained infrastructure where memory is limited, shards are in constant competition with each other for the OS Page Cache. If a user’s first query hits Replica A, the node loads that massive HNSW graph into its page cache from disk.
If the user refines their search or paginates, the default round-robin routing might send the next query to Replica B (on a different node). Now, Node B has to read from disk to load its cache, instantly evicting other vital data (LRU eviction).
This creates a vicious cycle of “cache thrashing.”
By adding a constant preference to your vector queries (e.g., _knn_search?preference=user_session_id), you override the round-robin behavior.
This deterministic routing guarantees that a user’s consecutive queries always land on the exact same shard. The cache stays “hot” for their session, stopping the internal competition for memory.
How it works:
OpenSearch hashes the preference string to select a specific replica for each shard. For example, with preference=abc and 3 shards (each with 1 replica), the
hash might assign:
– Shard 0 → always use primary (Node 1)
– Shard 1 → always use replica (Node 2)
– Shard 2 → always use primary (Node 3)
This means Node 1 will only serve Shard 0 for this user, keeping that specific 12GB HNSW graph, for example, warm in its page cache, while its other hosted shards (e.g., Shard 2 replica) remain cold and unused for this user’s queries.
Example (simplified):
Without preference (Round-robin):
Query 1 → Node A (Shard 0) → Disk read (600 IOPS)
Query 2 → Node B (Shard 0) → Disk read (600 IOPS) ❌
Query 3 → Node A (Shard 0) → Disk read again (600 IOPS) ❌
With preference (Deterministic):
Query 1 → Node A (Shard 0) → Disk read (600 IOPS)
Query 2 → Node A (Shard 0) → Cache hit (50 IOPS) ✅
Query 3 → Node A (Shard 0) → Cache hit (50 IOPS) ✅
In practice, this simple routing optimization has led to a 50% reduction in IOPS per query (dropping from 600 down to 302 IOPS) for our clients.
Trade-offs and when to use this
This optimization does introduce load imbalance, some nodes may handle more traffic than others for vector queries. However, this imbalance is often negligible in practice.
For example, if vector search represents only a small percentage of your total query volume, the actual cluster-wide imbalance is negligible, and within acceptable margins. The dramatic IOPS reduction outweighs this minor skew.
✅ Best suited for:
– Vector queries representing <10% of total traffic
– Cost-constrained deployments where RAM < total index size
❌ Avoid when:
– Vector queries dominate (>30% of traffic)
– Indexes already fit entirely in RAM
– Cluster is near saturation (load imbalance becomes critical)
Quantization
Another way to alleviate memory pressure on constrained infrastructure and stop cache evictions is leveraging native quantization features within OpenSearch.
OpenSearch currently supports:
- Scalar Quantization: Natively available for both the Lucene and Faiss engines. It compresses vectors into 8-bit integers, effectively dividing memory consumption by 4 with minimal accuracy loss.
- Product Quantization: Built directly into the Faiss engine, this technique divides vectors into smaller sub-vectors and clusters them, unlocking those massive 64x scale reductions.
- Binary Quantization: Also built into the Faiss engine, transforming high-dimensional floats into single bits for use cases requiring extreme scale.
By default scalar int8 quantization is applied.
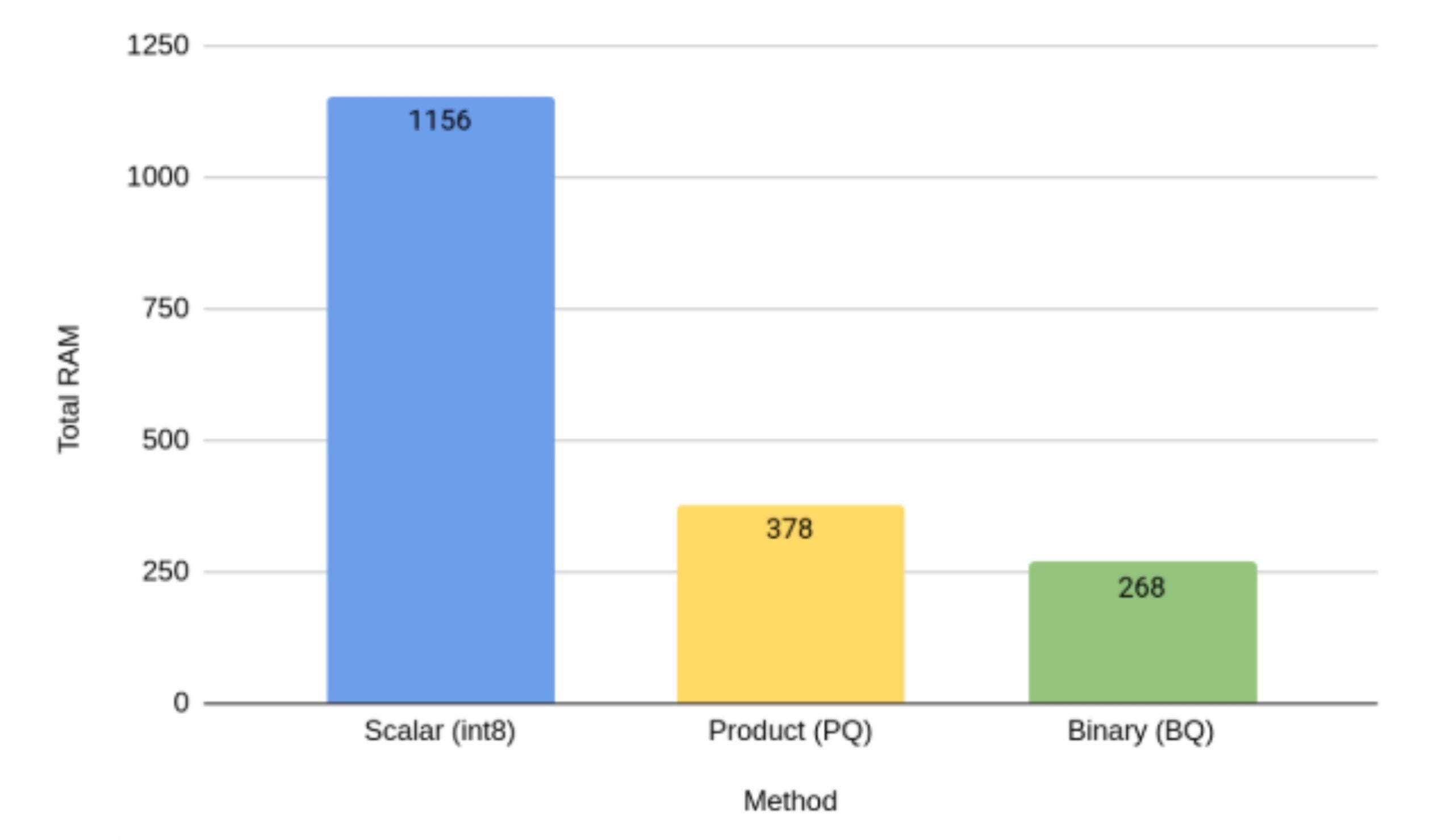
While the massive reductions illustrated above are impressive, they must always be balanced against retrieval accuracy.
Better recall with ADC and random rotation
In e-commerce, losing precision means returning the wrong product, and losing the sale.
If you implement aggressive memory-saving techniques, you must find a way to claw back that lost accuracy.
With the latest versions of OpenSearch, we can rely on two different mechanisms.
The first is Asymmetric Distance Computation (ADC). When calculating distance, you might assume both the query and the database vectors need to be compressed. This compounds precision loss. Instead, ADC heavily compresses the product vectors stored in your index while keeping the incoming user search query in its original, high-precision format (32-bit float).
Because OpenSearch calculates the distance between a raw query and a compressed document, you gain a massive boost to search recall without increasing your memory footprint.
The second is Random Rotation.
This technique is a lifesaver if your real-world e-commerce data is statistically unbalanced.
It applies a mathematical rotation to your entire vector space before quantization occurs, evenly distributing the data’s variance across all dimensions.
When the quantization algorithm then compresses the vector, it operates much more efficiently, drastically reducing approximation errors and preserving the subtle semantic meaning of your catalog.
The best part? You don’t need to build custom compression pipelines to achieve this.
OpenSearch natively integrates these techniques, and activating them is as simple as declaring them in your index mapping:
PUT /ecommerce-catalog { "settings": { "index": { "knn": true } }, "mappings": { "properties": { "product_vector": { "type": "knn_vector", "dimension": 768, "method": { "name": "hnsw", "engine": "faiss", "parameters": { "encoder": { "name": "bq", "parameters": { "random_rotation": true, "enable_adc": true } } } } } } } }
What this means in practice
Vector search provides a robust semantic fallback for queries that lexical query relaxing cannot resolve. However, its implementation in high-traffic e-commerce environments introduces significant resource demands. Maintaining response times below 100 ms requires a strategic approach to infrastructure.
ANN algorithms establish the baseline. Deterministic routing via the preference parameter reduced IOPS from 600 to 302 in observed scenarios. Scalar quantization compresses vectors into 8-bit integers, cutting memory consumption by four with minimal accuracy loss. Asymmetric Distance Computation and Random Rotation recover precision lost during compression without increasing the memory footprint.
Together, these techniques enable platforms to scale semantic search without exhausting RAM or triggering continuous cache evictions. The transition to semantic query relaxing is a balance between relevance algorithms and hardware efficiency.

