
New for version 2.4, Point in Time (PIT) is the preferred pagination method for OpenSearch. While OpenSearch still supports other ways of paginating results, PIT search provides superior capabilities and performance because it is not bound to a query and supports consistent pagination going both forward and backward.
OpenSearch pagination methods
There are four ways to paginate results in OpenSearch:
- The
fromandsizeparameters - The scroll search operation
- The
search_afterparameter - PIT with
search_after
What makes a good pagination method?
So, what are the desired characteristics of a good pagination method? It depends, of course, on your application. If you don’t need the ability to skip pages, you may be perfectly fine with the most basic scroll search. However, in general, here are the qualities of a good pagination method:
- Moving forward and backward: In addition to moving forward in search results, the user may want to go back to the page before the current page.
- Skipping pages: The user may want to skip to a page out of order.
- Consistency: The search results must stay consistent, even with live index updates. If the user is on Page 1 of the results, selects Page 2, and then goes back to Page 1, Page 1 stays the same despite documents being indexed or deleted in the meantime.
- Deep pagination: The search must stay efficient even when the user wants to view results starting with Page 1,000.
Pagination methods compared
Here is how OpenSearch pagination methods compare to each other.
| Pagination method | Can move forward and backward? | Consistent pagination? | Efficient for deep pagination? | Results not bound to a particular query? |
|---|---|---|---|---|
from and size parameters | ✔ | – | – | – |
| Scroll search | – | ✔ | – | – |
search_after parameter | ✔ | – | – | – |
PIT with search_after | ✔ | ✔ | ✔ | ✔ |
And the winner is…
As you can see, PIT with search_after is a clear winner because it checks all the boxes. Not only can it move both forward and backward in search results and provide consistent pagination while documents are being indexed and deleted, but it is also efficient for deep pagination. Plus, the results are frozen in time and not bound to a particular query, so you can run different queries against the same result dataset.
How PIT works
When you create a PIT for a set of indexes, OpenSearch takes the corresponding segments of the indexes’ shards and freezes them in time, creating contexts (pointers to the data) that you can use to access and query those shards.
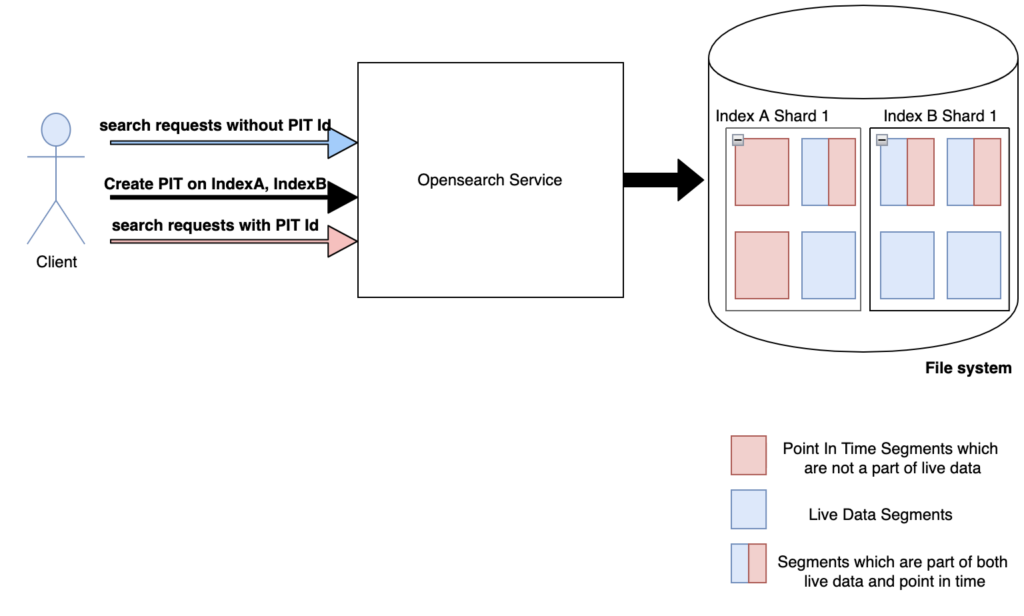
When you use a query with a PIT ID, it searches the segments that are frozen in time. Because a PIT is query agnostic, you can use any query to search the data in a PIT. PIT search allows for consistent pagination because even though the index continues to ingest and delete documents, the PIT does not reflect those changes and the dataset remains constant. Alternatively, if you use a normal query without a PIT ID, it searches live segments.
What’s the catch?
So far we’ve seen that PIT search is superior to other pagination methods. But what are the drawbacks? First, for a PIT, OpenSearch has to keep the segments even though they might have been merged and are not needed for the live dataset. This leads to an increased heap usage. Second, there is currently no built-in resiliency in a PIT, so if your node goes down, all PIT segments are lost.
How to use PIT search
The example in this section uses the shakespeare index.
Set up a sample index
Assuming you are not running the security plugin, you can set up the shakespeare index as follows:
- Download the mapping file:
wget http://media.sundog-soft.com/es7/shakes-mapping.json- Index the mapping file:
curl -H "Content-Type: application/json" -XPUT http://localhost:9200/shakespeare (https://localhost:9200/shakespeare) --data-binary "@shakes-mapping.json"- Download the
shakespearedataset:
wget http://media.sundog-soft.com/es7/shakespeare_7.0.json- Index the data into OpenSearch:
curl -H "Content-Type: application/json" -XPUT http://localhost:9200/shakespeare/_bulk (https://localhost:9200/shakespeare/_bulk) --data-binary "@shakespeare_7.0.json"Use the PIT functionality
Follow these steps to use the PIT functionality.
Step 1: Create a PIT
The following request creates a PIT that will be kept for 1 hour:
POST shakespeare/_search/point_in_time?keep_alive=1h
The response contains a PIT ID:
{
"pit_id" : "o8L8QAELc2hha2VzcGVhcmUWck5NRDE3SFNUZ3lRZmJEMW1COWRidwAWd21kTFZRWlZSQ2k2YmRDeWh4U2w3ZwAAAAAAAAAACBZ0aFdURzJZbVJIYVlxczBsbkZ4emVnARZyTk1EMTdIU1RneVFmYkQxbUI5ZGJ3AAA=",
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"creation_time" : 1669082665118
}
Step 2: Use the PIT ID for your search
The following request searches for all documents in the play “Hamlet,” sorted by speech number and then ID, and returns the first 20 results:
GET /_search
{
"size": 20,
"query": {
"match" : {
"play_name" : "Hamlet"
}
},
"pit": {
"id": "o8L8QAELc2hha2VzcGVhcmUWck5NRDE3SFNUZ3lRZmJEMW1COWRidwAWd21kTFZRWlZSQ2k2YmRDeWh4U2w3ZwAAAAAAAAAACBZ0aFdURzJZbVJIYVlxczBsbkZ4emVnARZyTk1EMTdIU1RneVFmYkQxbUI5ZGJ3AAA=",
"keep_alive": "100m"
},
"sort": [
{ "speech_number": "asc" },
{ "_id": "asc" }
]
}
Note that there is no need to specify the index because the PIT is already created against the shakespeare index. The optional keep_alive parameter that is passed in the search prolongs the PIT keep-alive period by 100 minutes.
The response contains the first 20 results. Here is the last result; you have to note its sort values to get the next batch of results:
{
"_index" : "shakespeare",
"_id" : "32652",
"_score" : null,
"_source" : {
"type" : "line",
"line_id" : 32653,
"play_name" : "Hamlet",
"speech_number" : 1,
"line_number" : "1.2.19",
"speaker" : "KING CLAUDIUS",
"text_entry" : "Or thinking by our late dear brothers death"
},
"sort" : [
1,
"32652"
]
}
To get the next 20 results, use the search_after parameter and specify the sort values of the last result in the first batch:
GET /_search
{
"size": 20,
"query": {
"match" : {
"play_name" : "Hamlet"
}
},
"pit": {
"id": "o8L8QAELc2hha2VzcGVhcmUWck5NRDE3SFNUZ3lRZmJEMW1COWRidwAWd21kTFZRWlZSQ2k2YmRDeWh4U2w3ZwAAAAAAAAAACBZ0aFdURzJZbVJIYVlxczBsbkZ4emVnARZyTk1EMTdIU1RneVFmYkQxbUI5ZGJ3AAA="
},
"sort": [
{ "speech_number": "asc" },
{ "_id": "asc" }
],
"search_after": [
1,
"32652"
]
}
To list all PITs, use the following request:
GET /_search/point_in_time/_all
When you’re done, you can delete the PIT:
DELETE /_search/point_in_time
{
"pit_id": "o8L8QAELc2hha2VzcGVhcmUWck5NRDE3SFNUZ3lRZmJEMW1COWRidwAWd21kTFZRWlZSQ2k2YmRDeWh4U2w3ZwAAAAAAAAAACBZ0aFdURzJZbVJIYVlxczBsbkZ4emVnARZyTk1EMTdIU1RneVFmYkQxbUI5ZGJ3AAA="
}
You can also get information about the PIT’s segments using the CAT PIT Segments API.
To learn more about all PIT APIs, see Point in Time API.
What’s next?
For more information about PIT search, see the PIT documentation section.
Next, we’re planning to release a PIT frontend that you can use in OpenSearch Dashboards. To track the frontend progress, see the PIT meta issue.






