
We are excited to announce that segment replication—a new replication strategy built on Lucene’s Near-Real-Time (NRT) Segment Index Replication API and introduced as experimental in OpenSearch 2.3—is generally available in OpenSearch 2.7. Implemented as an alternative to document replication, segment replication significantly increases indexing throughput while lowering compute costs for many use cases. With document replication, all replica nodes (referred to as a replica group) perform the same indexing operation as the primary node. With segment replication, only the primary node performs the indexing operation, creating segment files that are copied remotely to each node in the replica group. In this replication design, the heavy indexing workload is performed only on the primary node, freeing up resources on the replicas for scaling out other operations. In this blog post, we dive deep into the concept of segment replication, advantages and shortcomings as compared to document replication, and planned future enhancements. To find out if segment replication is the right choice for your use case, see Segment replication or document replication.
Core concepts
When you create an index in OpenSearch, you specify its number_of_shards (the default is 1), called primary shards, and number_of_replicas (the default is 1). Each replica is a full copy of the set of primary shards. If you have 5 primary shards and 1 replica for each of them, you have 10 total shards in your cluster. The data you send for indexing is randomly hashed across the primary shards and replicated by the primary shards to the replica or replicas.
Internally, each shard is an instance of a Lucene index—a Java library for reading and writing index structures. Lucene is a file-based, append-only search API. A segment is a portion of a Lucene index in a folder on disk. Each document you send for indexing is split across its fields, with indexed data for the fields stored in 20–30 different structures. Lucene holds these structures in RAM until they are eventually flushed to disk as a collection of files, called a segment.
Replicas are typically used for two different purposes: durability and scalability, where replica shards provide redundant searchable copies of the data in a cluster. OpenSearch guarantees that the primary and replica shard data is allocated to different nodes in the cluster, meaning that even if you lose a node, you don’t lose data. OpenSearch can automatically recreate the missing copies of any shard that may have been lost on a faulty node. If you are running in the cloud, where the cluster spans isolated data centers (AWS Availability Zones), you can increase resiliency by having two replicas across three zones. The second and subsequent replicas provide additional query capacity. You add more nodes along with the additional replicas to provide further parallelism for query processing.
Document replication
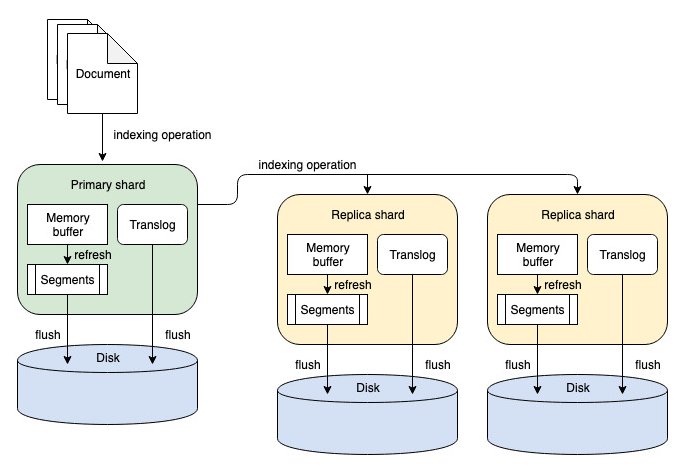
For versions 2.7 and earlier, document replication is the default replication mode. In this mode, all write operations that affect an index (for example, adding, updating, or removing documents) are first routed to the node containing the index’s primary shard. The primary shard is responsible for validating the operation and subsequently running it locally. Once the operation has completed successfully, the operation is forwarded in parallel to each node in the replica group. Each replica node in the group runs the same operation, duplicating the processing performed on the primary. When an operation has completed on a replica (either successfully or with a failure), a response is sent to the primary. Once all replicas in the group have responded, the primary node responds to the coordinating node, which sends a response to the client with detailed information about replication success or failure (for example, how many and which replica nodes may have failed).
The advantage of document replication is that documents become searchable on the replicas faster because they are sent to the replicas immediately following ingestion on the primary shard. The system reaches a consistent state between primary and replica shards as quickly as possible. However, document replication consumes more CPU because indexing operations are duplicated on every primary and replica for every document.
Refer to the following diagram of the document replication process.
Segment replication
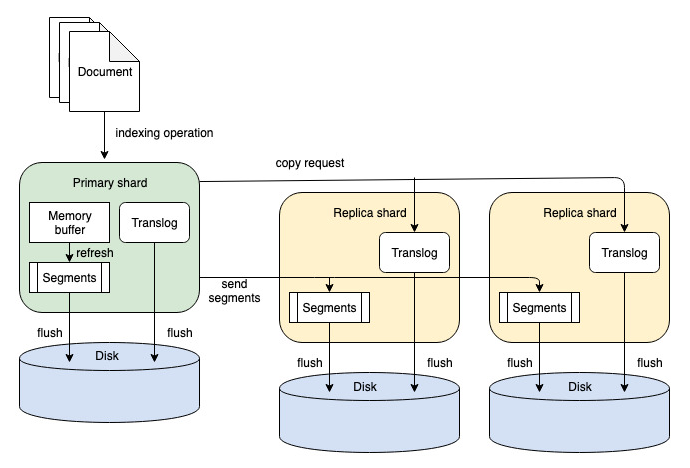
With segment replication, documents are indexed only on the node containing the primary shard. The resulting segment files are then copied directly to all replicas in a group and made searchable. Segment replication reduces the compute cost of adding, updating, or deleting documents by performing the CPU work only on the primary node. The underlying Lucene append-only index makes copying segments possible: as documents are added, updated, or deleted, Lucene creates new segments, but the existing segments are left untouched (deletes are soft and handled with tombstones and docvalue fields).
The advantage of segment replication is that it reduces the overall CPU usage in your cluster by removing the duplicated effort of parsing and processing the data in your documents. However, because all indexing and networking originates on the nodes with primary shards, those nodes become more heavily loaded. Additionally, nodes with primary shards spend time waiting for segment creation (this amount of time is controlled by the refresh_interval) and sending the segments to the replica, increasing the amount of time before a particular document is consistently searchable on every shard.
Refer to the following diagram of the segment replication process.
Segment replication test results
During benchmark ingestion testing with 10 primary shards and 1 replica on the stackoverflow dataset, segment replication provided an increased ingestion rate throughput of up to 25% as compared to document replication. For detailed benchmarking results, see the Benchmarks section.
Our experimental release users reported up to 40% higher throughput with segment replication than with document replication for the same cluster setup. With segment replication, you can get the same ingestion throughput with 9 nodes in a cluster as you would get with 15 nodes with document replication.
Understanding the tradeoffs
Segment replication trades CPU usage for time and networking. The primary shard sends larger blocks of data to its replicas less frequently. As replica count increases, the primary shard becomes a bottleneck, performing all indexing work and replicating all segments. In our testing, we saw consistent improvement for a replica count of one. As replica count grows, the improvement decreases linearly. Performance improvement in your cluster depends on the workload, instance types, and configuration. Be sure to test segment replication with your own data and queries to determine the benefits for your workload.
For higher replica counts, remote storage integration works better. With remote storage integration, the primary shard writes segments to an object store, such as Amazon Simple Storage Service (Amazon S3), Google Cloud Storage, or Azure Blob Storage. Replicas then load the segments from the object store in parallel, freeing the node with the primary shard from sending out large data blocks to all replicas. We are planning to introduce remote storage integration in a future release.
As with any distributed system, some cluster nodes can fall behind the tolerable or expected throughput levels. Nodes may not be able to catch up to the primary node for various reasons, such as heavy local search loads or network congestion. To monitor segment replication performance, see OpenSearch benchmark.
Segment replication or document replication
Segment replication is best suited for the following configurations:
- Your cluster deployment has low replica counts (1–2 replicas). This is typically true for log analytics deployments.
- Your deployment has a high ingestion rate and relatively low search volume.
- Your application is not sensitive to replication lag.
- The network bandwidth between the nodes is ample for the high volume of data transfer between nodes required for segment replication.
We recommend using document replication in the following use cases, where segment replication does not work well:
- Your cluster deployment has high replica counts (more than 3) and you value low replication lag. This is typically true of search deployments.
- Your deployment cannot tolerate replication lag. In deployments such as search deployments, where the data consistency between all replicas is critical, we do not recommend segment replication because of its high latency.
- Your deployment has insufficient network bandwidth for expedient data transfer for the number of replicas.
You can validate the replication lag across your cluster with the CAT Segment Replication API.
See the Benchmarks section for benchmarking test results.
Segment replication backpressure
In addition to the existing shard indexing backpressure, OpenSearch 2.7 introduces a new segment replication backpressure rejection mechanism that is disabled by default.
Shard indexing backpressure is a shard-level smart rejection mechanism that dynamically rejects indexing requests when your cluster is under strain. It transfers requests from an overwhelmed node or shard to other nodes or shards that are still healthy.
Segment replication backpressure monitors the replicas to ensure they are not falling behind the primary shard. If a replica has not synchronized to the primary shard within a set time limit, the primary shard will start rejecting requests when ingesting new documents in an attempt to slow down the indexing.
Enabling segment replication
To enable segment replication for your index, follow the step-by-step instructions in the documentation.
Benchmarks
The following benchmarks were collected with OpenSearch-benchmark using the stackoverflow and nyc_taxi datasets.
The benchmarks demonstrate the effect of the following configurations on segment replication:
Note: Your results may vary based on the cluster topology, hardware used, shard count, and merge settings.
Increasing the workload size
The following table lists benchmarking results for the nyc_taxi dataset with the following configuration:
- 10 m5.xlarge data nodes
- 40 primary shards, 1 replica each (80 shards total)
- 4 primary shards and 4 replica shards per node
| 40 GB primary shard, 80 GB total | 240 GB primary shard, 480 GB total | ||||||
|---|---|---|---|---|---|---|---|
| Document Replication | Segment Replication | Percent difference | Document Replication | Segment Replication | Percent difference | ||
| Store size | 85.2781 | 91.2268 | N/A | 515.726 | 558.039 | N/A | |
| Index throughput (number of requests per second) | Minimum | 148,134 | 185,092 | 24.95% | 100,140 | 168,335 | 68.10% |
| Median | 160,110 | 189,799 | 18.54% | 106,642 | 170,573 | 59.95% | |
| Maximum | 175,196 | 190,757 | 8.88% | 108,583 | 172,507 | 58.87% | |
| Error rate | 0.00% | 0.00% | 0.00% | 0.00% | 0.00% | 0.00% | |
As the size of the workload increases, the benefits of segment replication are amplified because the replicas are not required to index the larger dataset. In general, segment replication leads to higher throughput at lower resource costs than document replication in all cluster configurations, not accounting for replication lag.
Increasing the number of primary shards
The following table lists benchmarking results for the nyc_taxi dataset for 40 and 100 primary shards.
| 40 primary shards, 1 replica | 100 primary shards, 1 replica | ||||||
|---|---|---|---|---|---|---|---|
| Document Replication | Segment Replication | Percent difference | Document Replication | Segment Replication | Percent difference | ||
| Index throughput (number of requests per second) | Minimum | 148,134 | 185,092 | 24.95% | 151,404 | 167,391 | 9.55% |
| Median | 160,110 | 189,799 | 18.54% | 154,796 | 172,995 | 10.52% | |
| Maximum | 175,196 | 190,757 | 8.88% | 166,173 | 174,655 | 4.86% | |
| Error rate | 0.00% | 0.00% | 0.00% | 0.00% | 0.00% | 0.00% | |
As the number of primary shards increases, the benefits of segment replication over document replication decrease. While segment replication is still beneficial with a larger number of primary shards, the difference in performance becomes less pronounced because there are more primary shards per node that must copy segment files across the cluster.
Increasing the number of replicas
The following table lists benchmarking results for the stackoverflow dataset for 1 and 9 replicas.
| 10 primary shards, 1 replica | 10 primary shards, 9 replicas | ||||||
|---|---|---|---|---|---|---|---|
| Document Replication | Segment Replication | Percent difference | Document Replication | Segment Replication | Percent difference | ||
| Index throughput (number of requests per second) | Median | 72,598.10 | 90,776.10 | 25.04% | 16,537.00 | 14,429.80 | −12.74% |
| Maximum | 86,130.80 | 96,471.00 | 12.01% | 21,472.40 | 38,235.00 | 78.07% | |
| CPU usage (%) | p50 | 17 | 18.857 | 10.92% | 69.857 | 8.833 | −87.36% |
| p90 | 76 | 82.133 | 8.07% | 99 | 86.4 | −12.73% | |
| p99 | 100 | 100 | 0% | 100 | 100 | 0% | |
| p100 | 100 | 100 | 0% | 100 | 100 | 0% | |
| Memory usage (%) | p50 | 35 | 23 | −34.29% | 42 | 40 | −4.76% |
| p90 | 59 | 57 | −3.39% | 59 | 63 | 6.78% | |
| p99 | 69 | 61 | −11.59% | 66 | 70 | 6.06% | |
| p100 | 72 | 62 | −13.89% | 69 | 72 | 4.35% | |
| Error rate | 0.00% | 0.00% | 0.00% | 0.00% | 2.30% | 2.30% | |
As the number of replicas increases, the amount of time required for primary shards to keep replicas up to date (known as the replication lag) also increases. This is because segment replication copies the segment files directly from primary shards to replicas.
The benchmarking results show a non-zero error rate as the number of replicas increases. The error rate indicates that the segment replication backpressure mechanism is initiated when replicas cannot keep up with the primary shard. However, the error rate is offset by the significant CPU and memory gains that segment replication provides.
Other considerations
The following considerations apply to segment replication in the 2.7 release:
- Read-after-write guarantees: The
wait_untilrefresh policy is not compatible with segment replication. If you use thewait_untilrefresh policy while ingesting documents, you’ll get a response only after the primary node has refreshed and made those documents searchable. Replica shards will respond only after having written to their local translog. We are exploring other mechanisms for providing read-after-write guarantees. For more information, see the corresponding GitHub issue. - System indexes will continue to use document replication internally until read-after-write guarantees are available. In this case, document replication does not hinder the overall performance because there are few system indexes.
- Enabling segment replication for an existing index requires reindexing.
- Rolling upgrades are not yet supported. Upgrading to new versions of OpenSearch requires a full cluster restart.
What’s next?
The OpenSearch 2.7 release provides a peer-to-peer (node-to-node) implementation of segment replication. With this release, you can choose to use either document replication or segment replication based on your cluster configuration and workloads. In the coming releases, OpenSearch remote storage, our next-generation storage architecture, will use segment replication as the single replication mechanism. Segment-replication-enabled remote storage will eliminate network bottlenecks on primary shards for clusters with higher replica counts. We are also exploring a chain replication strategy to further alleviate the load on primary shards. For better usability, we are planning to integrate segment replication with OpenSearch Dashboards so that you can enable the feature using the Dashboards UI. We are also planning to provide quick support for rolling upgrades, making it easier to migrate to new versions without downtime.




