
















Boost OpenSearch vector search performance with Intel AVX-512
Introduced in OpenSearch 2.18, Intel Advanced Vector Extensions 512 (Intel AVX-512) is a set of new instructions that can accelerate vector workload performance. Vector search benchmarks using OpenSearch Benchmark showed performance boosts of up to 15% for indexing and up to 13% for search tasks when compared to the same workloads’ performance using AVX2, a predecessor of the technology.
Increasingly, application builders are using vector search to improve the search quality of their applications. This modern technique involves encoding content into numerical representations (vectors) that can be used to find similarities between content. With the rise in usage of large language models (LLMs) and generative AI, the workloads have increased from millions to billions of vectors. Maintaining ingestion and query performance for such huge workloads becomes critical given the increase in vector data size.
In this blog post, we will share the results of some popular OpenSearch workloads using Intel AVX-512 and AVX2 and compare their performance. The benchmarks were run using OpenSearch Benchmark and showcase how Intel AVX-512 provides a performance boost over AVX2 for fp32 and fp16 quantization using the Faiss library. The hardware accelerators are widely available on AWS, and 4th Generation Intel Xeon Scalable processors available as r7i were used for these benchmarks.
The importance of vectorization in OpenSearch vector search
Vector search uses advanced techniques like cosine similarity or Euclidean distance to quickly and efficiently find similar items. This is especially useful in the context of large datasets, for which traditional search methods are slower. Furthermore, vectorized data can be processed in parallel, making it highly scalable and ensuring that as the dataset grows, search performance remains optimal. Intel AVX-512 can further improve the vector search throughput by processing more vectors.
Why Intel AVX-512 performs better
The techniques used in vector search are computationally expensive, and Intel AVX-512 is well positioned to tackle these challenges. The accelerator can be used directly in several ways:
- For writing native code using intrinsics
- In compiler optimizations, such as auto-vectorization The corresponding optimized assembly instructions are generated when the accelerator is correctly utilized. AVX2 generates instructions using YMM registers, and AVX-512 generates instructions using ZMM registers. Performance is enhanced by allowing ZMM registers to handle 32 double-precision and 64 single-precision floating-point operations per clock cycle within 512-bit vectors. Additionally, these registers can process eight 64-bit and sixteen 32-bit integers. With up to two 512-bit fused multiply-add (FMA) units, AVX-512 effectively doubles the width of data registers, the number of registers, and the width of FMA units compared to Intel AVX2 YMM registers. Beyond these improvements, Intel AVX-512 offers increased parallelism, which leads to faster data processing and improved performance in compute-intensive applications such as scientific simulations, analytics, and machine learning. It also provides enhanced support for complex number calculations and accelerates tasks like cryptography and data compression. Furthermore, AVX-512 includes new instructions that improve the efficiency of certain algorithms, reduce power consumption, and optimize resource utilization, making it a powerful tool for modern computing needs.
By registering double width to 512 bits, the use of ZMM registers instead of YMM registers can potentially double the data throughput and computational power. When the AVX-512 extension is detected, the Faiss distance and scalar quantizer functions process 16 vectors per loop compared to 8 vectors per loop for the AVX2 extension.
Thus, in vector search using k-nearest neighbors (k-NN), index build times and vector search performance can be enhanced with the use of these new hardware extensions.
The hot spot in OpenSearch vector search
Because of single instruction, multiple data (SIMD) processing, AVX-512 helps reduce the number of cycles spent on hot functions during indexing and search for both inner product and L2 (Euclidean) space types, which is especially notable in the FP32-encoded indexing. The next section describes the hot functions observed during an OpenSearch benchmark execution and the corresponding improvements observed when the hot functions were vectorized using AVX-512. The baseline used is the AVX2 version of the Faiss library. % Cycles spent represents the percentage of time spent by the CPU on the particular function during the benchmark run.
Inner product space type
- FP32 encoding:
- Hot functions:
- faiss::fvec_inner_product
- faiss::fvec_inner_product_batch_4
- Benefits of AVX-512:
- Indexing: Up to 75% reduction in cycles
- Search: Up to 8% reduction in cycles
- Hot functions:
- SQfp16 encoding:
- Hot function: faiss::query_to_code
- Benefits of AVX-512:
- Indexing: Up to 39% reduction in cycles
- Search: Up to 11% reduction in cycles
The following table shows the percentage of total CPU cycles spent on key functions for indexing and search operations, comparing AVX2 and AVX-512 implementations.
| Encoding | Function | % Cycles spent (AVX2) | % Cycles spent (AVX-512) | |
|---|---|---|---|---|
| Indexing | FP32 | fvec_inner_product | 28.86 | 7.32 |
| Indexing | SQfp16 | query_to_code | 17.95 | 10.94 |
| Search | FP32 | fvec_inner_product_batch_4 | 34.66 | 31.74 |
| Search | SQfp16 | query_to_code | 42.24 | 37.73 |
L2 (Euclidean) space type
- FP32 encoding:
- Hot functions:
- faiss::fvec_L2sqr
- faiss::fvec_L2sqrt_batch_4
- Benefits of AVX-512:
- Indexing: Up to 54% reduction in cycles
- Search: Up to 11% reduction in cycles
- Hot functions:
- SQfp16 encoding:
- Hot function: faiss::query_to_code
- Benefits of AVX-512:
- Indexing: Up to 17% reduction in cycles
- Search: Up to 6% reduction in cycles
The following table shows the percentage of total CPU cycles spent on key functions for indexing and search operations, comparing AVX2 and AVX-512 implementations.
| Encoding | Function | % Cycles spent (AVX2) | % Cycles spent (AVX-512) | |
|---|---|---|---|---|
| Indexing | FP32 | fvec_L2sqr | 36.76 | 16.75 |
| Indexing | SQfp16 | query_to_code | 26.18 | 21.61 |
| Search | FP32 | fvec_L2sqr_bactch_4 | 31.80 | 28.32 |
| Search | SQfp16 | query_to_code | 36.99 | 34.72 |
Starting with OpenSearch version 2.18, AVX-512 is enabled by default. As of March 2025, OpenSearch has shown the best performance for AVX-512 on AWS r7i instances.
The next section describes the results of benchmarks run with AVX2 and AVX-512 versions of the Faiss library shipped for x64 architecture (for more information, see SIMD optimization. These benchmarks were run using the OpenSearch Benchmark vector search workload and the following benchmark configuration.
Results
The results show that the time spent on hot functions of the distance calculation is significantly reduced when using AVX-512, and the OpenSearch cluster shows higher throughput for search and indexing.
SQfp16 encoding provided by the Faiss library further helps with faster computation and efficient storage by compressing the 32-bit floating-point vectors into 16-bit floating-point format. The smaller memory footprint allows for more vectors to be stored in the same amount of memory. Additionally, the operations on the 16-bit floats are typically faster than those on the 32-bit floats, leading to faster similarity searches.
A greater performance improvement is observed between AVX-512 and AVX2 on FP16 because of code optimizations and the use of AVX-512 intrinsics in Faiss, which are not present in AVX2.
A general observation across all benchmarks is that AVX-512 improves performance because of a significant reduction in path length—the number of machine instructions needed to execute a workload.
COHERE-1M with FP32
Indexing operations demonstrate a 9% boost, while search throughput and latencies demonstrate a 7% and 6% improvement, respectively, compared to AVX2.
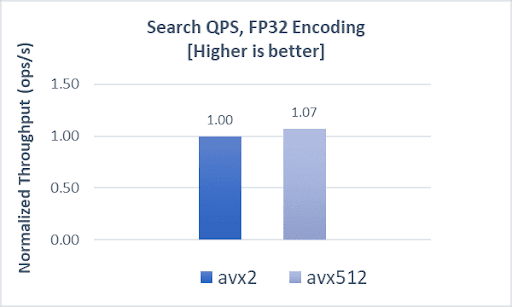
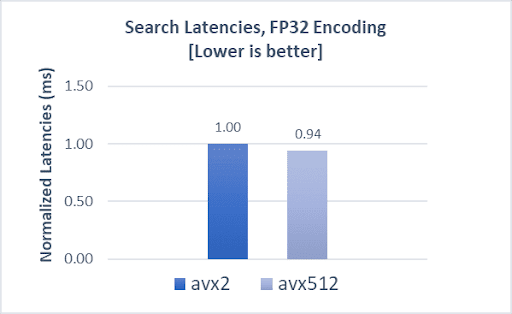
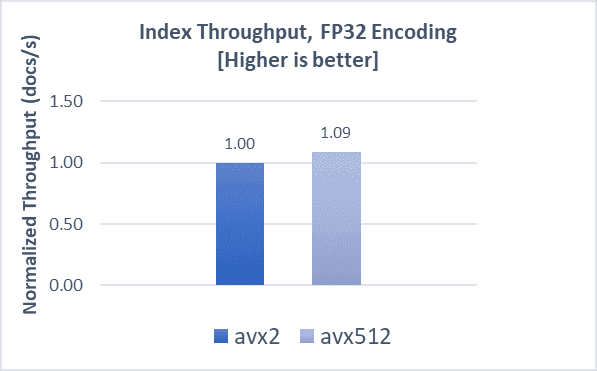
COHERE-1M with SQfp16
Indexing operations demonstrate an 11% boost, while search operations and latencies both demonstrate a 10% improvement when using AVX-512 compared to AVX2.
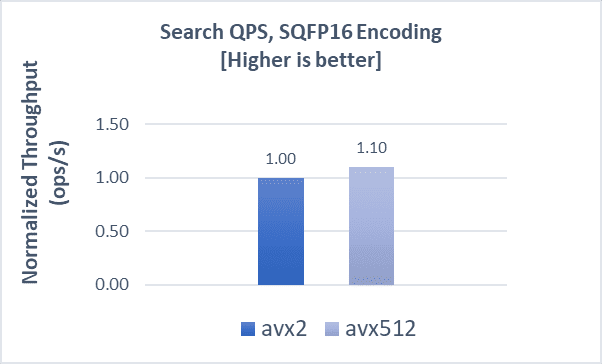
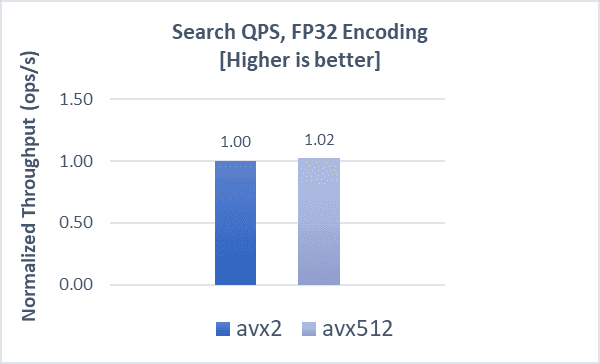
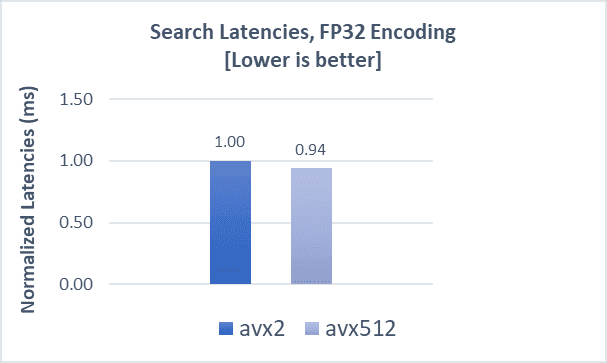
GIST-1M with FP32
Indexing operations demonstrate a 5% boost, while search throughput and latencies demonstrate a 2% and 6% improvement, respectively, compared to AVX2. While search throughput with the gist-1m dataset is not comparable to that of the cohere-1m dataset, the latency boost is maintained.
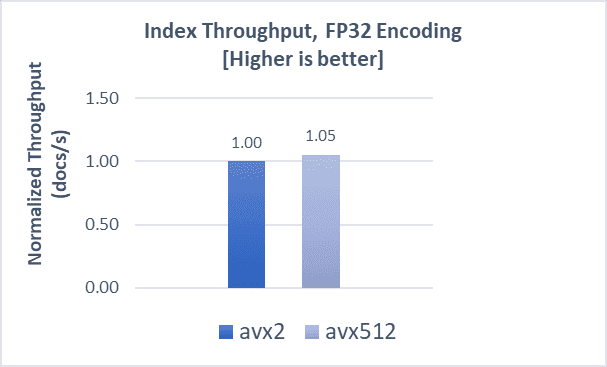
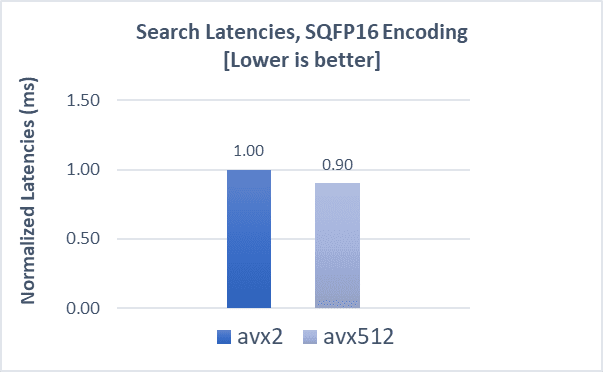
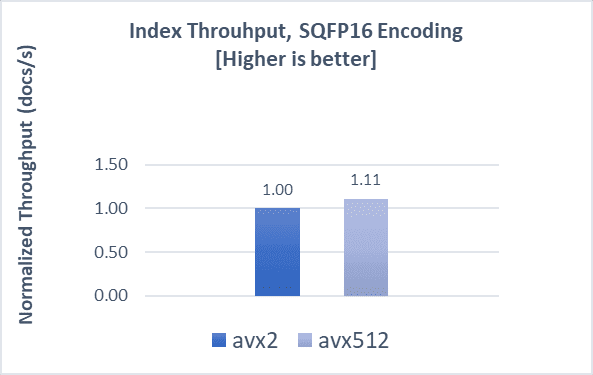
GIST-1M with SQfp16
Indexing operations demonstrate a 15% boost, while search throughput and latencies both demonstrate a 7% improvement compared to AVX2.
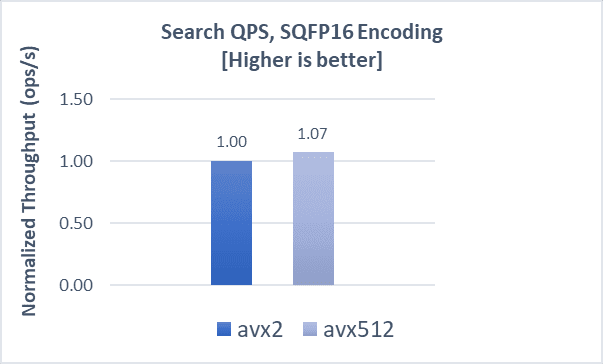
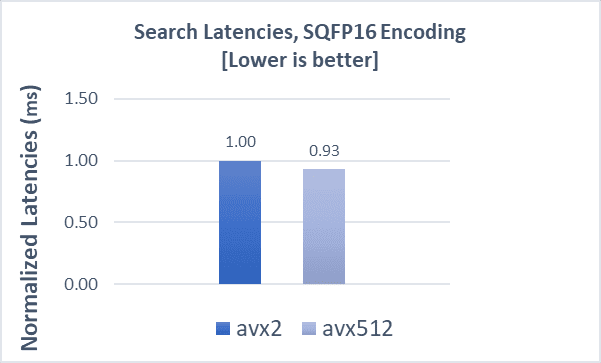
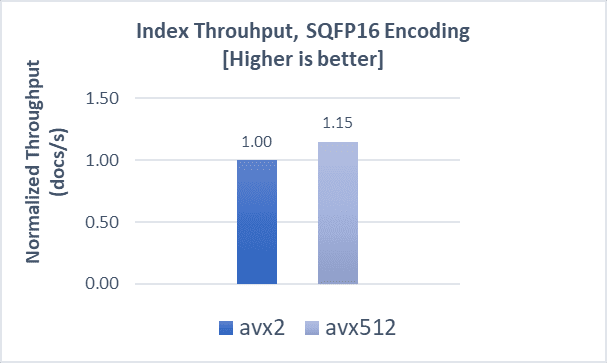
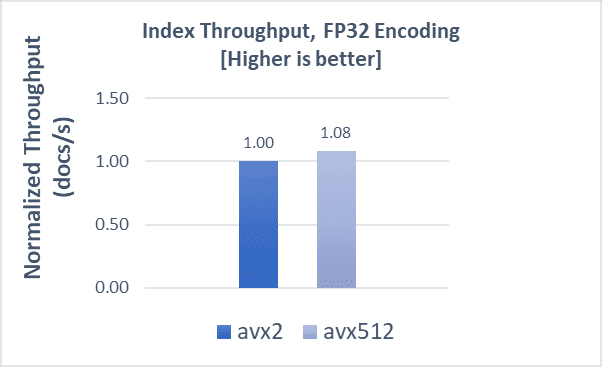
COHERE-10M with FP32
Indexing operations demonstrate a 8% boost, while search latencies demonstrate a 5% improvement compared to AVX2. Scaling search clients from 20 to 280 shows a QPS boost of up to 12% with AVX-512.
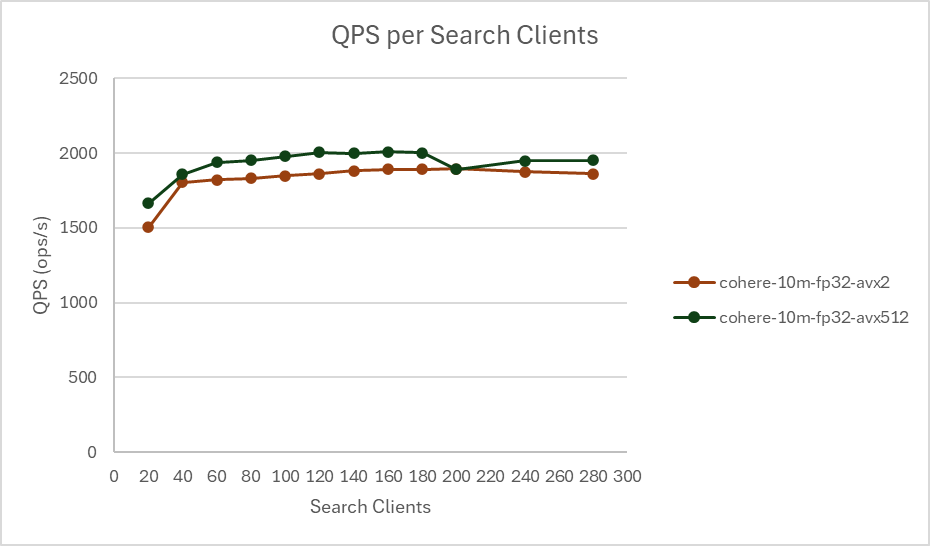
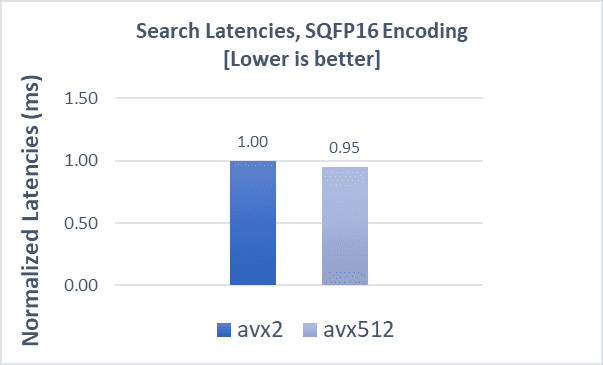
COHERE-10M with SQfp16
SQfp16 encoding with AVX-512 delivers a 6% performance boost in indexing and a 5% improvement in search latencies. Scaling search clients from 20 to 280 for throughput analysis shows a QPS boost of up to a 13%, with 10% lower latencies on average when using AVX-512.
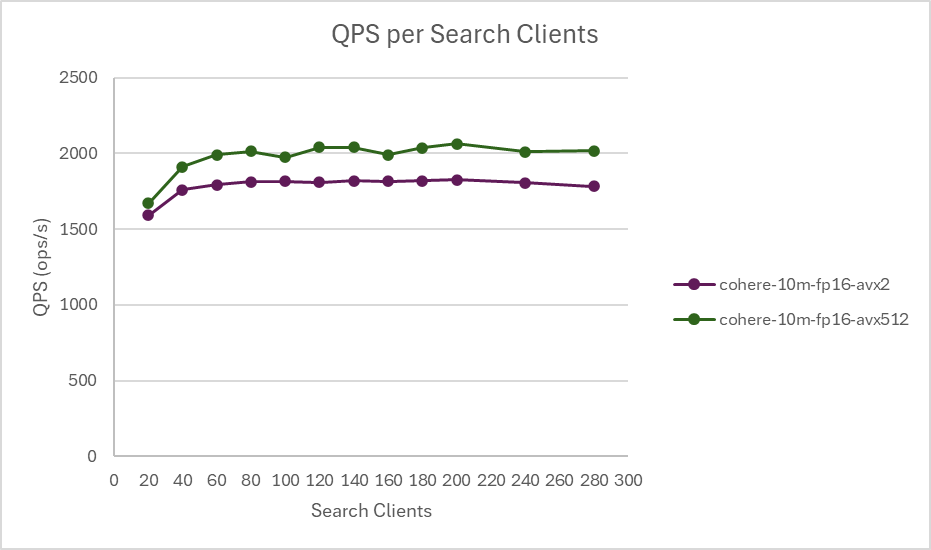

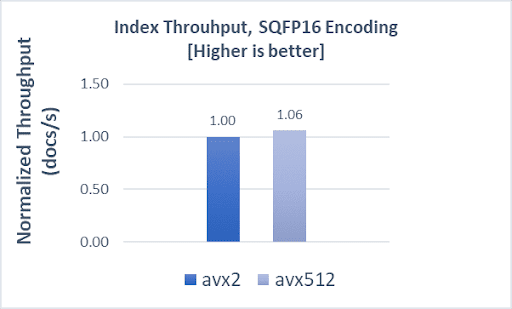
These results show how the Intel AVX-512 optimizations in the Faiss library can help improve the performance of vector search in multiple OpenSearch workloads with different dimensions and space types.
Conclusion
In this blog post, we highlighted some hot functions that appear during vector search using the Faiss library and showed how the Intel AVX-512 accelerator significantly boosts OpenSearch performance by optimizing these functions.
Our experiments showed a throughput increase of up to 15% for indexing and up to 13% for vector search in OpenSearch, when compared to previous-generation AVX2 accelerators. Gains are seen across multiple vector dimensions and vector space types, and query latencies are improved by 10% on average. These accelerators are present on Intel instances in most cloud environments, including AWS, and can be used seamlessly with OpenSearch.
To maximize performance in your OpenSearch cluster on AWS, consider using the Intel C7i, M7i, or R7i instances, which contain the latest AVX-512 accelerators, making them a great choice for vector search workloads.
Future improvements
To build on this work, we plan to use advanced features available in Intel 4th Generation Xeon Scalable and newer server processors. One key improvement will be using AVX512-FP16 arithmetic for the scalar quantizer. This is expected to further reduce search latencies and improve the indexing throughput of Faiss SQfp16 (2x compression in on_disk mode).
Notices and disclaimers
Search performance varies by use, configuration, and other factors. For more information, see the Performance Index overview. Performance results are based on testing as of the dates shown in the configurations and may not reflect all publicly available updates.
Intel technologies may require enabled hardware, software, or service activation.
Disclosure:
Remember that performance can be highly dependent on factors like data structure, query patterns, indexes, and more. It’s a good practice to test your application with different instance types and configurations in order to find the optimal setup that balances performance and cost for your specific use case.






