
The OpenSearch Project is excited to announce the general availability of searchable snapshots in OpenSearch. With searchable snapshots, you can search indexes that are stored as snapshots within remote repositories in real time without the need to restore the index data to local storage ahead of time. The relevant index data is retrieved on demand with the search request. Searchable snapshots cache data on local storage to improve performance. In this blog post, we will cover the design and implementation of searchable snapshots, their performance, and planned future enhancements.
Using a snapshot for search
Before searchable snapshots, searching data within a snapshot required restoring the entire snapshot to the OpenSearch cluster node. This involved expanding your infrastructure, which is costly and time consuming.
With searchable snapshots, you can search snapshots locally on your OpenSearch cluster. This way, you can search through less frequently accessed indexes saved as snapshots without having to restore them to the cluster beforehand.
The searchable snapshots feature caches frequently used data blocks in cluster nodes, using the Least Recently Used (LRU) caching strategy to remove the data blocks that are not accessed anymore in order to make space for the ones that are currently used. The data blocks downloaded from snapshots using the block mechanism reside alongside the general indexes of the cluster nodes. The local storage of the node is used for caching the data downloaded from the snapshot. Any subsequent searches on the cached data perform better because they are served from the node’s local storage, or cache, without the need to redownload the segment data from the snapshot. Therefore, you can search snapshots stored in lower-cost storage, such as Amazon Simple Storage Service (Amazon S3), Google Cloud Storage, or Azure Blob Storage, with acceptable performance.
The following image shows the creation of an index using a remote storage option, such as Amazon S3, Google Cloud Storage, or Azure Blob Storage.
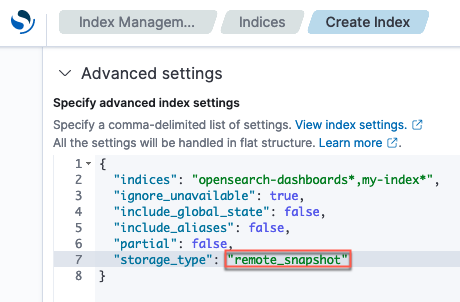
Enabling searchable snapshots in OpenSearch
To enable searchable snapshots, reference the instructions in the OpenSearch documentation.
Performance
Comparing the performance of searchable snapshot queries and local index queries on the stackoverflow dataset, the initial run of searchable snapshots took approximately twice as long as the local index. However, subsequent queries showed similar performance for both searchable snapshots and the local index because searchable snapshots used cached data.
The following table presents the time in seconds taken to scan approximately 36 million documents in the stackoverflow dataset using the Scroll API in a single-threaded test runner.
| Local index | Searchable snapshot | |
|---|---|---|
| First scan | 588 | 1233 |
| Repeat scan | 590 | 641 |
Note that in order to delete a snapshot, you must first delete all searchable snapshot indexes created from that snapshot.
Benchmarks
The benchmark data was collected using the nyc_taxi dataset. For the following benchmarks, the OpenSearch benchmark nyc_taxis workload was configured with 0 warmup iterations so that the cache was not populated when the measurements started. The test aimed to achieve 1.5 operations per second. search_clients was configured to 16 to match the number of CPU cores on the hosts. For searchable snapshots, the test was performed immediately after creating the searchable snapshot index.
| Local index | Searchable snapshot | |
|---|---|---|
| Throughput (search ops/s) | ||
| Minimum | 0.45 | 0.05 |
| Mean | 1.48 | 1.38 |
| Median | 1.50 | 1.45 |
| Max | 1.50 | 1.47 |
| Latency (ms) | ||
| p50 | 1,065.84 | 1,111.07 |
| p90 | 1,099.68 | 1,162.98 |
| p99 | 1,177.59 | 11,287.20 |
| p99.9 | 2,212.63 | 20,595.50 |
| p100 | 2,212.72 | 20,596.00 |
When to use searchable snapshots
Use searchable snapshots on infrequently accessed read-only data that is not sensitive to latency during first-time access. This works well for log analytics use cases where older data is not modified and is generally queried less frequently than the newest data.
Industries like law and healthcare require data to be retained for set amounts of time. In these cases, searchable snapshots can serve as a lightweight mechanism for searching historical data stored in snapshots. When you need to search older data, you can restore its snapshot to the hot cluster to enable searching. Searchable snapshots can now be used for search, with the expectation that the search may not be as fast.
Things to consider
Here are a couple of things to keep in mind when using searchable snapshots:
- No prefetch logic: In the absence of any prefetch algorithm, data is not fetched until there is an explicit search on the data segment. This will cause every initial search to be slow.
- When managing resource-intensive searches on snapshot data, other OpenSearch cluster activities, like indexing, may be slower.
Future enhancements
The following are planned future enhancements to searchable snapshots:
- Searching on a remote store index (mutable)
- Intelligent prefetch
- Safeguards against long or large searches, avoiding impact on hot node activities
- Concurrent search to improve search performance
Try searchable snapshots
Make sure to download OpenSearch 2.7 and try out searchable snapshots. For detailed information about searchable snapshots, see Searchable snapshots in the OpenSearch documentation.


