
First time here?
Have you only recently heard of OpenSearch and are curious just what it is? Here’s some help getting on your feet. First, about indexing and full text search as a core function. Also, how OpenSearch extends those things into something more than a search library. OpenSearch provides a basis for many useful workflows meant to analyze, visualize, and aggregate data.
So what is OpenSearch then?
OpenSearch is an open-source project built on top of Apache Lucene, a powerful indexing and search library. Even if you’ve never heard of an indexing library before, you’re still probably more familiar with indexing than you think. The quantity of data businesses maintain in this age necessitates it. Apache Lucene provides OpenSearch the ability to maintain large volumes of full documents, arbitrary text as well as non-textual data while maintaining several indices to make searching through each of them efficient.
What is it used for?
The use cases for OpenSearch are many. Here are a few popular examples.
Log ingestion takes advantage of the full-text search capabilities against the unpredictability of data in log files. Indexing all the various data types encountered makes finding specific tokens (say, an IP address or a specific error message from a specific host) in a collection of log lines a short task. In distributed applications, this is even more useful. Summarize and aggregate an entire cluster’s logs using OpenSearch Dashboards. Throw in a bit of anomaly detection and some visualizations for some extra insight.
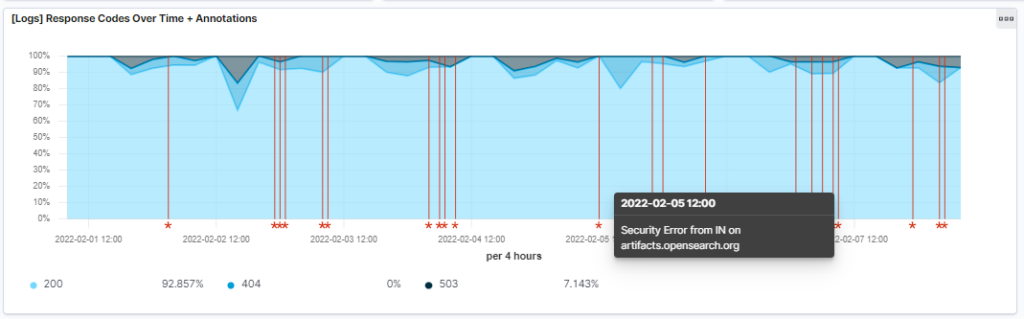
This example is a stacked graph of response codes over time. Certain events are configured to trigger an anomaly warning. It’s a short example of what visualizations are capable of.
Building your own custom search engine is another use for which OpenSearch is fully capable. Using the OpenSearch client library gives you access to ranked search, field weighting, and many other features common for search engines. Results are scored based on the frequency of the terms searched, how many documents contain that term, and how many times they contain it, amongst other criteria. OpenSearch can weigh the results as well. For example, matches against a document’s title can be considered a more meaningful match than matching terms in a document’s content.
See for yourself.
The quickest way to get hands-on is to bring up OpenSearch. Inspect the sample datasets and visualizations to get a feel for it. It is the straightest path to exemplifying what all can be done. Visit the downloads page and follow the instructions to get started.
After logging into OpenSearch Dashboards with admin:admin you’ll see the home screen.
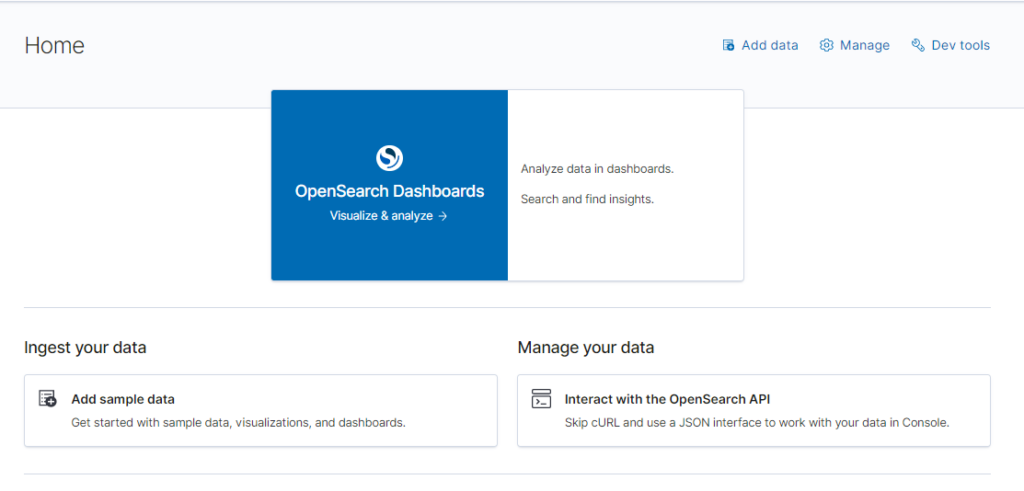
Click ‘Add Data’ in the upper right or ‘Add Sample Data’ in the lower left – you’ll be shown three sample data sets. There’s no harm in installing all three of them.
There’s nothing like seeing it in action! The sample data sets offered come with dashboards that are excellent examples of the visualizations and how the information is structured. What you see here is the dashboard that comes with some test data for a fake airline company. Heat maps, stacked graphs, pie charts, gauges and bar charts are available, among others.
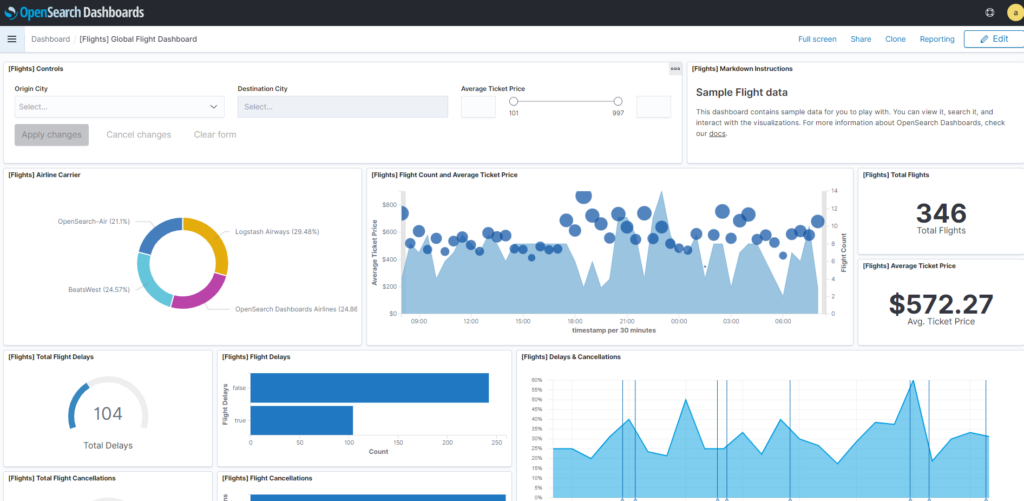
A wide selection of visualizations are available. Arrange them on a Dashboard to get a view that’s just right.
All set, but it’s just the start.
Hopefully some of the uncertainty about what OpenSearch is and what it does has been cleared up. Its base functionality has a wide variety of use cases, such as building a custom search engine. Also, ingesting logs for the ease of searching and aggregating. Both make use of the strong indexing and search library under the hood. OpenSearch Dashboards extends this even further by allowing you to build the exact view you want. Even ones that can warn you of anomalies in your data.
A closing thought.
Anyone can help. Really. This project wouldn’t be where it is today without the community. One of the project’s principles of development is to be “Open source like we mean it.” The participation of anyone willing will always be welcome. Assistance and contributions of any kind are helpful whether you’re a blogger, coder, tech writer, graphic designer, thought leader or jack of all trades. Not all contributions are code! If you’ve enjoyed this, become part of the community! Check out the project page on GitHub, and the public roadmap. Also, join the community meetings. Last but not least, get involved in discussions and chat with other community members in the OpenSearch Forums. All are welcome and come as you are.
