
















Introducing OpenSearch 2.9.0
OpenSearch 2.9.0 is ready to download, with new features designed to help you build better search solutions and integrate more machine learning (ML) into your applications, along with updates for security analytics workloads, geospatial visualizations, and more. This release also provides new compression codecs that offer significant performance improvements and reduced index sizes. For developers, an experimental extensions software development kit (SDK) simplifies the work of building features and functionality on top of OpenSearch. Following are some highlights from the latest version of OpenSearch and OpenSearch Dashboards; for a comprehensive view, please see the release notes.
Power up your search with search pipelines
Search practitioners are looking to introduce new ways to enhance search queries as well as results. With the general availability of search pipelines, you can configure a list of one or more processors to transform search requests and responses inside of OpenSearch. By integrating processors for functions like query rewriters or results rerankers directly in OpenSearch, you can make your search applications more accurate and efficient and reduce the need for custom development.
Search pipelines incorporate three built-in processors, filter_query, rename_field, and script request, as well as new developer-focused APIs to enable developers who want to build their own processors to do so. You can explore search pipelines for yourself in the OpenSearch Playground. These capabilities are an ongoing priority for learning and development for the project; if you’d like to share input on new processors or other ideas, please see the request for comments.
Build semantic search applications more easily
The OpenSearch Project released experimental neural search functionality in OpenSearch 2.4.0. With the 2.9.0 release, neural search is production-ready for your search workloads. These tools allow you to vectorize documents and queries and search those transformed vectors using k-nearest neighbors (k-NN), so you can take advantage of OpenSearch’s vector database capabilities to power applications like semantic search. Now you can combine traditional BM25 lexical search with deep-learning-powered semantic search and unlock new ways to tune your queries for improved search relevancy.
Integrate and manage your ML models in your OpenSearch cluster
Applications like semantic search call for integrated ML models. This release makes it easier to operationalize and integrate ML models with the general availability of the ML framework. Released as the model-serving framework in 2.4.0 as an experimental feature, this framework lets you upload your own ML models to OpenSearch, with support for text-embedding models from a number of tools, such as PyTorch and ONNX, and it does the heavy lifting of preparing models for deployment for neural search and other applications. As part of readying the framework for general availability, OpenSearch 2.9.0 also introduces ML model access control. This feature allows administrators to govern access to individual models that are integrated through the framework.
Integrate externally managed ML models
OpenSearch 2.9.0 expands the functionality of the ML framework by enabling integrators to create connectors to artificial intelligence (AI) services and ML platforms with low effort—requiring them only to define a blueprint in JSON. These AI connectors enable users to use models hosted on the connected services and platforms to power ML workloads like the ones required by semantic search. Instructions for building connectors are included in the documentation. As an example of this capability, this release includes a connector for Amazon SageMaker–hosted models. The project will publish connectors for Cohere Rerank and OpenAI ChatGPT in the near future, with additional integrations to follow.
Augment search with vector database enhancements
With this release, OpenSearch’s approximate k-NN implementation supports pre-filtering for queries using the Facebook AI Similarity Search (FAISS) engine. Now you can filter queries using metadata prior to performing nearest neighbors searches on k-NN indexes built with FAISS, offering more efficient k-NN search and better performance. Previously, OpenSearch only supported pre-filtering for Lucene indexes.
Another update to OpenSearch k-NN comes with support for Lucene’s byte-sized vectors. Users now have the option to ingest and use vectors that have been quantized to the size of one byte per dimension instead of four. This reduces storage and memory requirements for loading, saving, and performing vector search, at the cost of a potential decrease in accuracy.
Build monitors and detectors in OpenSearch Dashboards
Now you can see your alerts and anomalies directly overlaid with the primary dashboards you use to monitor your environments. By integrating OpenSearch’s alerting and anomaly detection tools with OpenSearch visualization tools, this release helps streamline the work of users who monitor systems and infrastructure. Users can also create alerting monitors or anomaly detectors directly from their OpenSearch Dashboards VISLIB chart or line visualizations, then view alerts or anomalies overlaid on the configured visualizations. Users with monitors or detectors already defined can now associate them with a visualization. This eliminates the need for users to shift between visualization tools and the information needed to create alerts or anomaly detectors, making it easier to explore data and identify discoveries.
Use composite monitors for more meaningful alerting notifications
New in 2.9.0, composite monitors mark another addition to OpenSearch’s alerting toolkit. Composite monitors allow users to chain alerts generated by multiple individual monitors into a single workflow. Users are notified when the combined trigger conditions across the monitors are met. This enables users to analyze data sources based on multiple criteria and gain more granular insights into their data. Now users have the opportunity to create targeted notifications while reducing the overall volume of alerts.
Improve performance with new index compression options
OpenSearch provides built-in codecs that perform compression on indexes, impacting the size of index files and the performance of indexing operations. Previous versions included two codec types: a default index codec, which prioritizes performance over compression, and a best_compression codec, which achieves high compression and smaller index sizes with potential increases in CPU usage during indexing, and can result in higher latencies. With the 2.9.0 release, OpenSearch adds two new codecs, zstd and zstd_no_dict, which use Facebook’s Zstandard compression algorithm. Both codecs aim to balance compression and performance, with zstd_no_dict excluding the dictionary compression feature for potential gains in indexing and search performance at the expense of slightly larger index sizes.
These new zstd and zstd_no_dict codecs provide an option to configure the compression level as an index setting (index.codec.compression_level). This is not available for other codecs. Compression level offers a trade-off between compression ratio and speed; a higher compression level results in a lower storage size but more CPU resources spent on compression. Optimizing these trade-offs depends on several aspects of the workload, and the best way to optimize for overall performance is to try multiple levels.
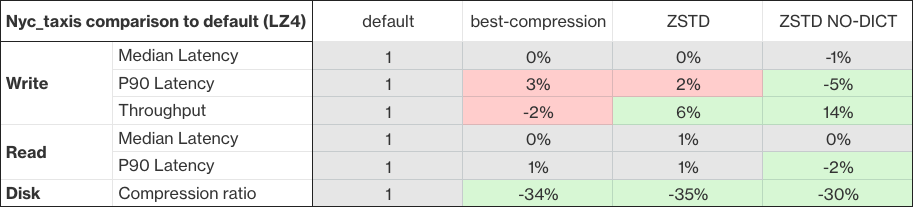
As seen above, tests conducted using the NYC Taxis dataset show the potential for significant improvements in compression of up to 35% with zstd compared to the default codec, with throughput increases of up to 7% for zstd and 14% for zstd_no_dict. After upgrading to 2.9.0, users can realize performance improvements by modifying the settings of a new or existing index.
Simplify threat detection with Security Analytics
Security Analytics now supports a new ingestion schema for log data that follows the Open Cybersecurity Schema Framework (OCSF), enabling OCSF logs from Amazon Route 53, AWS CloudTrail, and Amazon Virtual Private Cloud (Amazon VPC). Also now generally available is the correlation engine for OpenSearch Security Analytics. You can create custom correlation rules that display a visual knowledge graph and a list of findings across different log sources like DNS, Netflow, and Active Directory. The knowledge graph can be used in your security investigations to analyze associated findings, helping you to identify threat patterns and relationships across different systems. Using this knowledge graph can help you respond faster to potential security threats in your organization.
Aggregate metrics for geospatial shape data
OpenSearch stores geospatial data using geoshape and geopoint field types. Users were able to perform aggregations on geopoint data types in previous versions; with the release of 2.9.0, OpenSearch also supports aggregations for geoshape data types as a backend functionality accessible through the API. This release adds support for geoshapes to three types of aggregations: geo_bounds, a metric aggregation that computes the bounding box containing all geo values in a field; geo_hash, a multi-bucket aggregation that groups geoshapes into buckets representing cells in a grid; and geo_tile, a multi-bucket aggregation that groups geoshapes into buckets representing map tiles.
Monitor the health of your shards and indexes
OpenSearch provides a range of metrics to help you monitor the health of your OpenSearch cluster. This release adds CAT shards and CAT indices monitors. These updates allow you to monitor the state of all primary and replica shards along with information related to index health and resource usage to support operational uptime.
Extend OpenSearch’s functionality with a new SDK
The OpenSearch Project maintains a library of plugins that extend the functionality of OpenSearch across different workloads and use cases. For a number of reasons, plugins run within the OpenSearch process, meaning that they must maintain version compatibility and that their resources scale with the OpenSearch cluster. For developers, building new plugins requires considerable familiarity with OpenSearch’s architecture and code base.
Some developers have asked for an approach to building OpenSearch-compatible tools that mitigates these limitations. To start to address this, this release introduces an experimental SDK that gives developers the tools to build extensions for OpenSearch. The OpenSearch Extensions SDK provides codified interfaces for communicating with OpenSearch and other installed plugins and extensions, allows extensions to be decoupled from OpenSearch versions, decouples resources, and introduces many other changes designed to make it easier for developers to build, and users to deploy, new innovations on OpenSearch. To access the SDK, check out the opensearch-sdk-java repo.
Getting started
You can download the latest version of OpenSearch here and explore OpenSearch Dashboards live on the Playground. For more information about this release, see the release notes and the documentation release notes. We would appreciate your feedback on this release on the community forum!
Got plans for September 27–29? We hope you’ll consider joining us for OpenSearchCon 2023. This annual gathering for the OpenSearch community brings users and developers from across the OpenSearch ecosystem together in Seattle, and you’re invited!
