
The OpenSearch Project is growing quickly and currently has around 600+ contributors who actively participate in the project day to day. The project releases the OpenSearch and OpenSearch Dashboards distributions along with standalone components.
For distribution release, OpenSearch follows a release train (now moving to a release window model) wherein a new version is released approximately every 6 weeks with dozens of plugins, supporting multiple architectures (x64, ARM64) and various distribution types (for example, Linux, RPM/DEB, Windows, Docker). Check out the release process documentation for more details.
Along with distribution releases, we also release standalone components, including half a dozen language clients (for example, Java, JavaScript, Ruby, Go, Python, and Rust), data ingestion tools such as Data Prepper, and integration tools (for example, Logstash or Fluentd) on regular basis. Standalone components are self-contained products that are published across diverse platforms, demanding unique handling of credentials and unique release process. Recognizing the need for efficiency and reduced error rates, we have aimed to automate our release process and make it self-serviceable. This article discusses the technical challenges we faced, our motivations for restructuring, and our approach to designing a sustainable and scalable release process.
Motivation
After the fork, the release process for components such as OpenSearch clients (opensearch-py, opensearch-java), OpenSearch drivers (JDBC, ODBC), and Data Prepper required extensive amounts of time and effort. It took between 45 minutes and 2 hours to release a single component. The release process was manual and required step-by-step execution of a detailed set of documented instructions. This approach proved to be arduous and time consuming. Additionally, the availability of credentials for different platforms was limited to a small group of individuals, causing a bottleneck in the release process. This created a dependency on the availability of these credential owners, which further hindered timely product releases. Moreover, this manual process was susceptible to human error. In certain cases, products had to be built on an ad-hoc basis, resulting in inconsistencies within the build environment.
To address these challenges, we recognized the need for a centralized and reusable release process that would support both current and future products within the OpenSearch ecosystem while minimizing the need for human intervention. By implementing such a solution, we aimed to overcome the dependency on individual credential owners and streamline the release workflow. This centralized approach will enhance efficiency, reduce errors, and pave the way for smoother releases across all OpenSearch products.
Challenges
- Change in build environment between releases: Due to infrequent usage, release workflows are less commonly tested as compared to CI checks. Consequently, building in a new environment, which may lack the necessary packages or precise package versions, increases the risk of producing artifacts that differ from the intended ones.
- Signing of the artifacts: To ensure the integrity of our released artifacts, we strive to sign all of them whenever possible. However, the existing signing system for OpenSearch posed complexities. Despite these challenges, we prioritized the implementation of a robust signing process. Our goal was to establish strict controls, auditing capabilities, and monitoring mechanisms to effectively manage and track all signed OpenSearch products.
- Blast radius: Our utmost priority was to minimize the potential impact and scope of any security breaches involving credentials, keys, and accounts used by the OpenSearch Project. In addition, we aimed to ensure seamless credentials rotation in case of emergencies or maintenance. However, achieving this goal posed a challenge due to the need for stringent management requirements for accounts, credentials, and keys as well as the restriction of access to a limited group of individuals. This complicated our decentralization efforts.
- Bottlenecks: Restricting access to a limited number of individuals inadvertently created bottlenecks in the release process. This approach increased the likelihood of delays and errors due to dependencies on the availability of these individuals. Moreover, the reliance on a select few also amplified the risk of human errors during the release process.
- Release reviews: The OpenSearch Project release process follows a standardized approach across repositories and is supervised by a dedicated release manager, typically a maintainer. One of the challenges we faced during automation was implementing robust checks to ensure the accuracy of the tag, the associated commit, and the inclusion of all scoped changes. It required careful consideration and effort to create a reliable mechanism that would validate these critical aspects of the release.
One-click release process end-to-end workflow
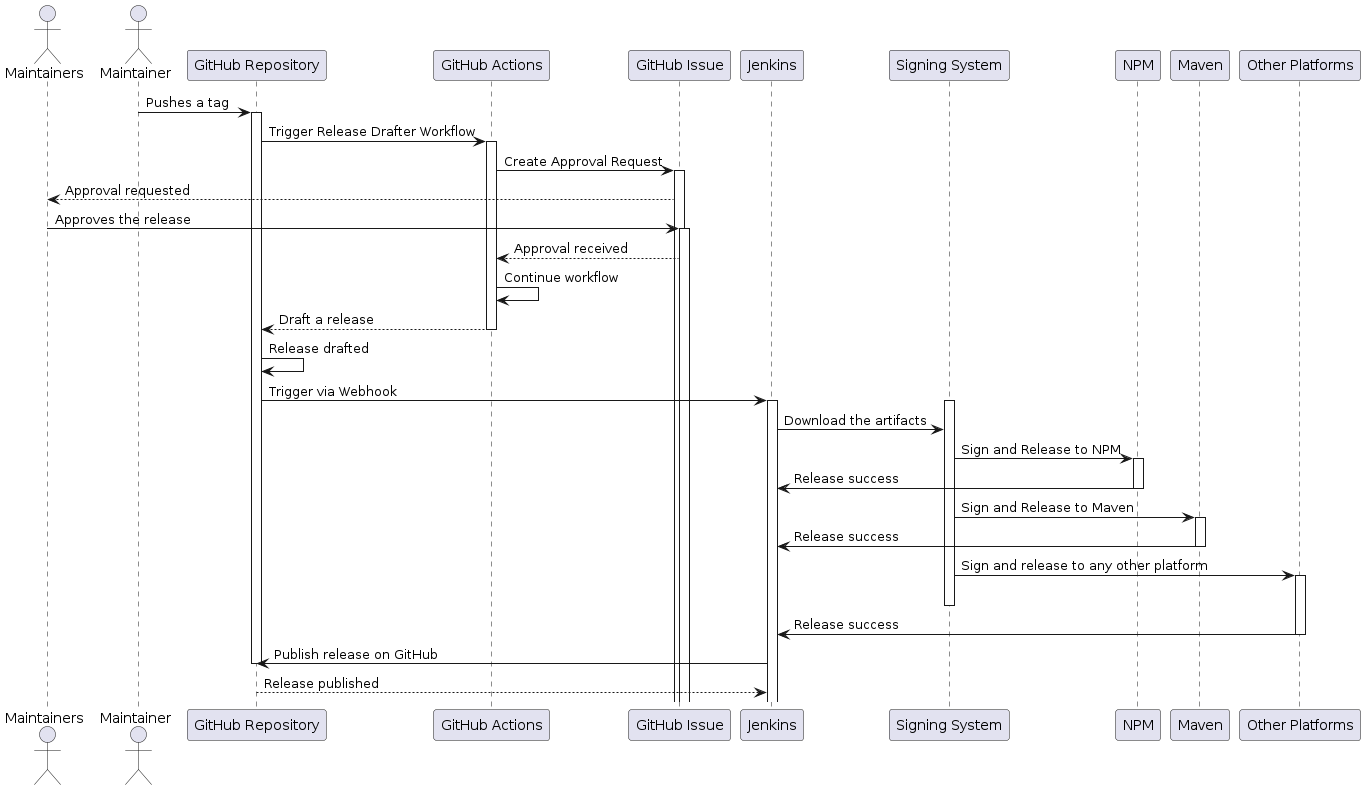 Figure 1: One-click release process end-to-end workflow
Figure 1: One-click release process end-to-end workflow
Solutions
The solutions to overcoming the above-mentioned challenges were implemented by using the following components.
Using a centralized CI/CD system for signing and releasing
Implementing a centralized CI/CD system (Jenkins in this scenario) has provided us with a comprehensive solution for managing credentials, accounts, and other requirements essential to signing and releasing our products. By adopting this centralized approach, we streamlined our processes and created a unified platform that serves as a convenient hub for all these tasks.
Moreover, Jenkins enabled us to establish automation through reusable libraries which are shared by similar components across the project. These build libraries play a crucial role in our release process and contribute to its efficiency.
The centralized nature of our system has also proven valuable in terms of auditing, logging, and monitoring the various components released as part of the OpenSearch Project. We can easily track and analyze the release activities across the project, ensuring transparency and accountability.
Building the artifacts on regularly exercised GitHub runners
To ensure a consistent and synchronized build environment between the development and the release, we made a deliberate decision to refrain from building anything on the release infrastructure. This approach effectively reduces maintenance effort and eliminates unexpected issues during the release process. Moreover, it significantly enhances our confidence in the product being shipped, as we can rely on a familiar and up-to-date build environment.
Using GitHub draft releases as the staging environment
Once the component has been built using GitHub Action workflows, we found that leveraging GitHub draft releases proved to be an excellent solution for storing interim products. This approach eliminated the need for maintaining an additional set of credentials to upload artifacts to a separate storage infrastructure.
Two-person review/approval of the release using a GitHub issue
To mitigate potential errors in the release process, we implemented a two-person review system. While the release is initiated by one of the maintainers of the respective GitHub repository, we recognized the importance of an additional layer of scrutiny. Thus, we introduced a release drafter workflow that automatically generates a GitHub issue within the same repository. This issue is assigned to all maintainers and contains crucial information such as commit ID, tag name, and version.
This approach allows other maintainers to thoroughly review the release before proceeding. They have the ability to approve or deny the release after carefully examining the provided information. By incorporating this two-person review process, we enhance the accuracy and quality of our releases, reducing the likelihood of human error and ensuring a higher level of confidence in the final product. See a sample issue that is created as a part of two person review process requesting approvals from other maintainers.
Minimal human intervention
Our end-to-end release process is designed to minimize human intervention, thus reducing the potential for errors. At this stage, the only task that requires human involvement is pushing a tag to the applicable GitHub repository. By streamlining the process and automating the majority of the steps, we have significantly mitigated the risk of human error. This approach ensures a more efficient and reliable release, enhancing overall productivity and maintaining a high level of accuracy throughout the process.
Future scope
We have made significant progress in the improvement of our release process, transitioning from a documented set of steps to a simplified approach that only requires pushing a tag to the applicable GitHub repository. This evolution represents a substantial improvement in terms of efficiency and effectiveness.
However, our journey doesn’t end here. We remain committed to continuous improvement and iteration of our release process. Our long-term objective is to expand this streamlined approach beyond standalone components. We aim to extend the process to encompass the release of the OpenSearch and OpenSearch Dashboards distributions, which include multiple plugins bundled with core engines. By doing so, we will further enhance the consistency and reliability of our overall release strategy, ensuring a seamless experience for our users.
Additional resources
- GitHub meta issue: https://github.com/opensearch-project/opensearch-build/issues/1234
- Onboarding document for this release process: https://github.com/opensearch-project/opensearch-build/blob/main/ONBOARDING.md#onboarding-to-universal–1-click-release-process
- Sample releasing document: https://github.com/opensearch-project/opensearch-java/blob/main/RELEASING.md#releasing

