You're viewing version 2.5 of the OpenSearch documentation. This version is no longer maintained. For the latest version, see the current documentation. For information about OpenSearch version maintenance, see Release Schedule and Maintenance Policy.
Anomaly detection
An anomaly in OpenSearch is any unusual behavior change in your time-series data. Anomalies can provide valuable insights into your data. For example, for IT infrastructure data, an anomaly in the memory usage metric might help you uncover early signs of a system failure.
It can be challenging to discover anomalies using conventional methods such as creating visualizations and dashboards. You could configure an alert based on a static threshold, but this requires prior domain knowledge and isn’t adaptive to data that exhibits organic growth or seasonal behavior.
Anomaly detection automatically detects anomalies in your OpenSearch data in near real-time using the Random Cut Forest (RCF) algorithm. RCF is an unsupervised machine learning algorithm that models a sketch of your incoming data stream to compute an anomaly grade and confidence score value for each incoming data point. These values are used to differentiate an anomaly from normal variations. For more information about how RCF works, see Random Cut Forests.
You can pair the anomaly detection plugin with the alerting plugin to notify you as soon as an anomaly is detected.
To get started, choose Anomaly Detection in OpenSearch Dashboards. To first test with sample streaming data, you can try out one of the preconfigured detectors with one of the sample datasets.
Step 1: Define a detector
A detector is an individual anomaly detection task. You can define multiple detectors, and all the detectors can run simultaneously, with each analyzing data from different sources.
- Choose Create detector.
- Add in the detector details.
- Enter a name and brief description. Make sure the name is unique and descriptive enough to help you to identify the purpose of the detector.
- Specify the data source.
- For Data source, choose the index you want to use as the data source. You can optionally use index patterns to choose multiple indices.
- (Optional) For Data filter, filter the index you chose as the data source. From the Data filter menu, choose Add data filter, and then design your filter query by selecting Field, Operator, and Value, or choose Use query DSL and add your own JSON filter query.
- Specify a timestamp.
- Select the Timestamp field in your index.
- Define operation settings.
- For Operation settings, define the Detector interval, which is the time interval at which the detector collects data.
-
The detector aggregates the data in this interval, then feeds the aggregated result into the anomaly detection model. The shorter you set this interval, the fewer data points the detector aggregates. The anomaly detection model uses a shingling process, a technique that uses consecutive data points to create a sample for the model. This process needs a certain number of aggregated data points from contiguous intervals.
-
We recommend setting the detector interval based on your actual data. If it’s too long it might delay the results, and if it’s too short it might miss some data. It also won’t have a sufficient number of consecutive data points for the shingle process.
-
- (Optional) To add extra processing time for data collection, specify a Window delay value.
- This value tells the detector that the data is not ingested into OpenSearch in real time but with a certain delay. Set the window delay to shift the detector interval to account for this delay.
- For example, say the detector interval is 10 minutes and data is ingested into your cluster with a general delay of 1 minute. Assume the detector runs at 2:00. The detector attempts to get the last 10 minutes of data from 1:50 to 2:00, but because of the 1-minute delay, it only gets 9 minutes of data and misses the data from 1:59 to 2:00. Setting the window delay to 1 minute shifts the interval window to 1:49 - 1:59, so the detector accounts for all 10 minutes of the detector interval time.
- For Operation settings, define the Detector interval, which is the time interval at which the detector collects data.
- Specify custom result index.
- If you want to store the anomaly detection results in your own index, choose Enable custom result index and specify the custom index to store the result. The anomaly detection plugin adds an
opensearch-ad-plugin-result-prefix to the index name that you input. For example, if you inputabcas the result index name, the final index name isopensearch-ad-plugin-result-abc.
You can use the dash “-” sign to separate the namespace to manage custom result index permissions. For example, if you use
opensearch-ad-plugin-result-financial-us-group1as the result index, you can create a permission role based on the patternopensearch-ad-plugin-result-financial-us-*to represent the “financial” department at a granular level for the “us” area.- If the custom index you specify doesn’t already exist, the anomaly detection plugin creates this index when you create the detector and start your real-time or historical analysis.
- If the custom index already exists, the plugin checks if the index mapping of the custom index matches the anomaly result file. You need to make sure the custom index has valid mapping as shown here: anomaly-results.json.
- To use the custom result index option, you need the following permissions:
indices:admin/create- If the custom index already exists, you don’t need this.indices:data/write/index- You need thewritepermission for the anomaly detection plugin to write results into the custom index for a single-entity detector.indices:data/read/search- You need thesearchpermission because the anomaly detection plugin needs to search custom result indices to show results on the anomaly detection UI.indices:data/write/delete- Because the detector might generate a large number of anomaly results, you need thedeletepermission to delete old data and save disk space.indices:data/write/bulk*- You need thebulk*permission because the anomaly detection plugin uses the bulk API to write results into the custom index.
- Managing the custom result index:
- The anomaly detection dashboard queries all detectors’ results from all custom result indices. Having too many custom result indices might impact the performance of the anomaly detection plugin.
- You can use Index State Management to rollover old result indices. You can also manually delete or archive any old result indices. We recommend reusing a custom result index for multiple detectors.
- If you want to store the anomaly detection results in your own index, choose Enable custom result index and specify the custom index to store the result. The anomaly detection plugin adds an
- Choose Next.
After you define the detector, the next step is to configure the model.
Step 2: Configure the model
Add features to your detector
A feature is the field in your index that you want to check for anomalies. A detector can discover anomalies across one or more features. You must choose an aggregation method for each feature: average(), count(), sum(), min(), or max(). The aggregation method determines what constitutes an anomaly.
For example, if you choose min(), the detector focuses on finding anomalies based on the minimum values of your feature. If you choose average(), the detector finds anomalies based on the average values of your feature.
A multi-feature model correlates anomalies across all its features. The curse of dimensionality makes it less likely for multi-feature models to identify smaller anomalies as compared to a single-feature model. Adding more features might negatively impact the precision and recall of a model. A higher proportion of noise in your data might further amplify this negative impact. Selecting the optimal feature set is usually an iterative process. By default, the maximum number of features for a detector is 5. You can adjust this limit with the plugins.anomaly_detection.max_anomaly_features setting.
To configure an anomaly detection model based on an aggregation method, follow these steps:
- On the Configure Model page, enter the Feature name and check Enable feature.
- For Find anomalies based on, select Field Value.
- For aggregation method, select either average(), count(), sum(), min(), or max().
- For Field, select from the available options.
To configure an anomaly detection model based on a JSON aggregation query, follow these steps:
- On the Configure Model page, enter the Feature name and check Enable feature.
- For Find anomalies based on, select Custom expression. You will see the JSON editor window open up.
- Enter your JSON aggregation query in the editor.
For acceptable JSON query syntax, see OpenSearch Query DSL
(Optional) Set category fields for high cardinality
You can categorize anomalies based on a keyword or IP field type.
The category field categorizes or slices the source time series with a dimension like IP addresses, product IDs, country codes, and so on. This helps to see a granular view of anomalies within each entity of the category field to isolate and debug issues.
To set a category field, choose Enable a category field and select a field. You can’t change the category fields after you create the detector.
Only a certain number of unique entities are supported in the category field. Use the following equation to calculate the recommended total number of entities supported in a cluster:
(data nodes * heap size * anomaly detection maximum memory percentage) / (entity model size of a detector)
To get the entity model size of a detector, use the profile detector API. You can adjust the maximum memory percentage with the plugins.anomaly_detection.model_max_size_percent setting.
This formula provides a good starting point, but make sure to test with a representative workload.
For example, for a cluster with three data nodes, each with 8 GB of JVM heap size, a maximum memory percentage of 10% (default), and the entity model size of the detector as 1MB: the total number of unique entities supported is (8.096 * 10^9 * 0.1 / 1 MB ) * 3 = 2429.
If the actual total number of unique entities higher than this number that you calculate (in this case: 2429), the anomaly detector makes its best effort to model the extra entities. The detector prioritizes entities that occur more often and are more recent.
(Advanced settings) Set a shingle size
Set the number of aggregation intervals from your data stream to consider in a detection window. It’s best to choose this value based on your actual data to see which one leads to the best results for your use case.
The anomaly detector expects the shingle size to be in the range of 1 and 60. The default shingle size is 8. We recommend that you don’t choose 1 unless you have two or more features. Smaller values might increase recall but also false positives. Larger values might be useful for ignoring noise in a signal.
Preview sample anomalies
Preview sample anomalies and adjust the feature settings if needed. For sample previews, the anomaly detection plugin selects a small number of data samples—for example, one data point every 30 minutes—and uses interpolation to estimate the remaining data points to approximate the actual feature data. It loads this sample dataset into the detector. The detector uses this sample dataset to generate a sample preview of anomaly results.
Examine the sample preview and use it to fine-tune your feature configurations (for example, enable or disable features) to get more accurate results.
- Choose Preview sample anomalies.
- If you don’t see any sample anomaly result, check the detector interval and make sure you have more than 400 data points for some entities during the preview date range.
- Choose Next.
Step 3: Set up detector jobs
To start a real-time detector to find anomalies in your data in near real-time, check Start real-time detector automatically (recommended).
Alternatively, if you want to perform historical analysis and find patterns in long historical data windows (weeks or months), check Run historical analysis detection and select a date range (at least 128 detection intervals).
Analyzing historical data helps you get familiar with the anomaly detection plugin. You can also evaluate the performance of a detector with historical data to further fine-tune it.
We recommend experimenting with historical analysis with different feature sets and checking the precision before moving on to real-time detectors.
Step 4: Review and create
Review your detector settings and model configurations to make sure that they’re valid and then select Create detector.
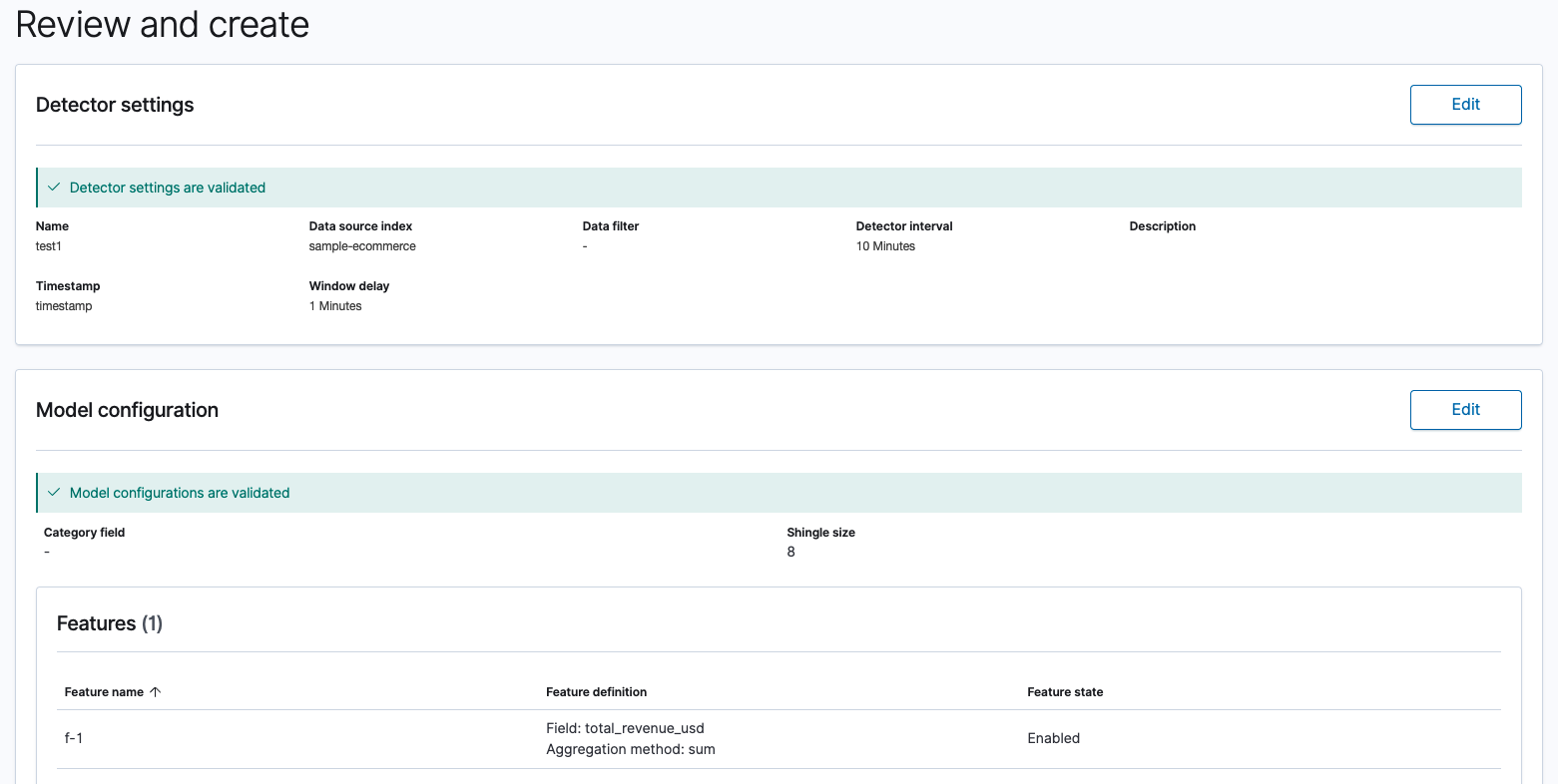
If you see any validation errors, edit the settings to fix the errors and then return back to this page.
Step 5: Observe the results
Choose the Real-time results or Historical analysis tab. For real-time results, you need to wait for some time to see the anomaly results. If the detector interval is 10 minutes, the detector might take more than an hour to start, because its waiting for sufficient data to generate anomalies.
A shorter interval means the model passes the shingle process more quickly and starts to generate the anomaly results sooner. Use the profile detector operation to make sure you have sufficient data points.
If you see the detector pending in “initialization” for longer than a day, aggregate your existing data using the detector interval to check for any missing data points. If you find a lot of missing data points from the aggregated data, consider increasing the detector interval.
Choose and drag over the anomaly line chart to zoom in and see a more detailed view of an anomaly.
Analyze anomalies with the following visualizations:
- Live anomalies (for real-time results) displays live anomaly results for the last 60 intervals. For example, if the interval is 10, it shows results for the last 600 minutes. The chart refreshes every 30 seconds.
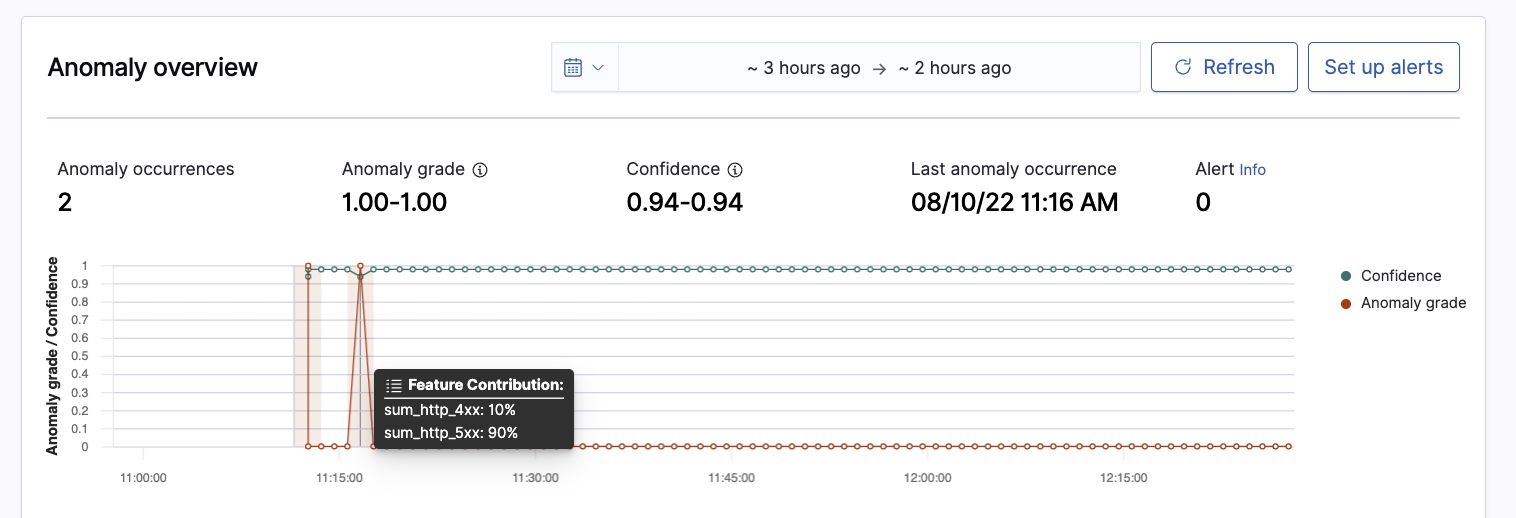
- Anomaly overview (for real-time results) / Anomaly history (for historical analysis in the Historical analysis tab) plots the anomaly grade with the corresponding measure of confidence. This pane includes:
- The number of anomaly occurrences based on the given data-time range.
- The Average anomaly grade, a number between 0 and 1 that indicates how anomalous a data point is. An anomaly grade of 0 represents “not an anomaly,” and a non-zero value represents the relative severity of the anomaly.
- Confidence estimate of the probability that the reported anomaly grade matches the expected anomaly grade. Confidence increases as the model observes more data and learns the data behavior and trends. Note that confidence is distinct from model accuracy.
- Last anomaly occurrence is the time at which the last anomaly occurred.
Underneath Anomaly overview/Anomaly history are:
-
Feature breakdown plots the features based on the aggregation method. You can vary the date-time range of the detector. Selecting a point on the feature line chart shows the Feature output, the number of times a field appears in your index, and the Expected value, a predicted value for the feature output. Where there is no anomaly, the output and expected values are equal.
-
Anomaly occurrences shows the
Start time,End time,Data confidence, andAnomaly gradefor each detected anomaly.
Selecting a point on the anomaly line chart shows Feature Contribution, the percentage of a feature that contributes to the anomaly
If you set the category field, you see an additional Heat map chart. The heat map correlates results for anomalous entities. This chart is empty until you select an anomalous entity. You also see the anomaly and feature line chart for the time period of the anomaly (anomaly_grade > 0).
If you have set multiple category fields, you can select a subset of fields to filter and sort the fields by. Selecting a subset of fields lets you see the top values of one field that share a common value with another field.
For example, if you have a detector with the category fields ip and endpoint, you can select endpoint in the View by dropdown menu. Then, select a specific cell to overlay the top 20 values of ip on the charts. The anomaly detection plugin selects the top ip by default. You can see a maximum of 5 individual time-series values at the same time.
Step 6: Set up alerts
Under Real-time results, choose Set up alerts and configure a monitor to notify you when anomalies are detected. For steps to create a monitor and set up notifications based on your anomaly detector, see Monitors.
If you stop or delete a detector, make sure to delete any monitors associated with it.
Step 7: Adjust the model
To see all the configuration settings for a detector, choose the Detector configuration tab.
- To make any changes to the detector configuration, or fine tune the time interval to minimize any false positives, go to the Detector configuration section and choose Edit.
- You need to stop real-time and historical analysis to change its configuration. Confirm that you want to stop the detector and proceed.
- To enable or disable features, in the Features section, choose Edit and adjust the feature settings as needed. After you make your changes, choose Save and start detector.
Step 8: Manage your detectors
To start, stop, or delete a detector, go to the Detectors page.
- Choose the detector name.
- Choose Actions and select Start real-time detectors, Stop real-time detectors, or Delete detectors.