Pipelines
The following image illustrates how a pipeline works.
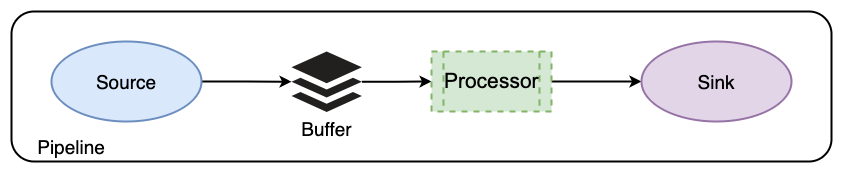
To use Data Prepper, you define pipelines in a configuration YAML file. Each pipeline is a combination of a source, a buffer, zero or more processors, and one or more sinks. For example:
simple-sample-pipeline:
workers: 2 # the number of workers
delay: 5000 # in milliseconds, how long workers wait between read attempts
source:
random:
buffer:
bounded_blocking:
buffer_size: 1024 # max number of records the buffer accepts
batch_size: 256 # max number of records the buffer drains after each read
processor:
- string_converter:
upper_case: true
sink:
- stdout:
-
Sources define where your data comes from. In this case, the source is a random UUID generator (
random). -
Buffers store data as it passes through the pipeline.
By default, Data Prepper uses its one and only buffer, the
bounded_blockingbuffer, so you can omit this section unless you developed a custom buffer or need to tune the buffer settings. -
Processors perform some action on your data: filter, transform, enrich, etc.
You can have multiple processors, which run sequentially from top to bottom, not in parallel. The
string_converterprocessor transform the strings by making them uppercase. -
Sinks define where your data goes. In this case, the sink is stdout.
Starting from Data Prepper 2.0, you can define pipelines across multiple configuration YAML files, where each file contains the configuration for one or more pipelines. This gives you more freedom to organize and chain complex pipeline configurations. For Data Prepper to load your pipeline configuration properly, place your configuration YAML files in the pipelines folder under your application’s home directory (e.g. /usr/share/data-prepper).
End-to-end acknowledgments
Data Prepper ensures the durability and reliability of data written from sources and delivered to sinks through end-to-end (E2E) acknowledgments. An E2E acknowledgment begins at the source, which monitors a batch of events set inside pipelines and waits for a positive acknowledgment when those events are successfully pushed to sinks. When a pipeline contains multiple sinks, including sinks set as additional Data Prepper pipelines, the E2E acknowledgment sends when events are received by the final sink in a pipeline chain.
Alternatively, the source sends a negative acknowledgment when an event cannot be delivered to a sink for any reason.
When any component of a pipeline fails and is unable to send an event, the source receives no acknowledgment. In the case of a failure, the pipeline’s source times out. This gives you the ability to take any necessary actions to address the source failure, including rerunning the pipeline or logging the failure.
Conditional routing
Pipelines also support conditional routing which allows you to route events to different sinks based on specific conditions. To add conditional routing to a pipeline, specify a list of named routes under the route component and add specific routes to sinks under the routes property. Any sink with the routes property will only accept events that match at least one of the routing conditions.
In the following example, application-logs is a named route with a condition set to /log_type == "application". The route uses Data Prepper expressions to define the conditions. Data Prepper only routes events that satisfy the condition to the first OpenSearch sink. By default, Data Prepper routes all events to a sink which does not define a route. In the example, all events route into the third OpenSearch sink.
conditional-routing-sample-pipeline:
source:
http:
processor:
route:
- application-logs: '/log_type == "application"'
- http-logs: '/log_type == "apache"'
sink:
- opensearch:
hosts: [ "https://opensearch:9200" ]
index: application_logs
routes: [application-logs]
- opensearch:
hosts: [ "https://opensearch:9200" ]
index: http_logs
routes: [http-logs]
- opensearch:
hosts: [ "https://opensearch:9200" ]
index: all_logs
Examples
This section provides some pipeline examples that you can use to start creating your own pipelines. For more pipeline configurations, select from the following options for each component:
The Data Prepper repository has several sample applications to help you get started.
Log ingestion pipeline
The following example pipeline.yaml file with SSL and basic authentication enabled for the http-source demonstrates how to use the HTTP Source and Grok Prepper plugins to process unstructured log data:
log-pipeline:
source:
http:
ssl_certificate_file: "/full/path/to/certfile.crt"
ssl_key_file: "/full/path/to/keyfile.key"
authentication:
http_basic:
username: "myuser"
password: "mys3cret"
processor:
- grok:
match:
# This will match logs with a "log" key against the COMMONAPACHELOG pattern (ex: { "log": "actual apache log..." } )
# You should change this to match what your logs look like. See the grok documenation to get started.
log: [ "%{COMMONAPACHELOG}" ]
sink:
- opensearch:
hosts: [ "https://localhost:9200" ]
# Change to your credentials
username: "admin"
password: "admin"
# Add a certificate file if you are accessing an OpenSearch cluster with a self-signed certificate
#cert: /path/to/cert
# If you are connecting to an Amazon OpenSearch Service domain without
# Fine-Grained Access Control, enable these settings. Comment out the
# username and password above.
#aws_sigv4: true
#aws_region: us-east-1
# Since we are Grok matching for Apache logs, it makes sense to send them to an OpenSearch index named apache_logs.
# You should change this to correspond with how your OpenSearch indexes are set up.
index: apache_logs
This example uses weak security. We strongly recommend securing all plugins which open external ports in production environments.
Trace analytics pipeline
The following example demonstrates how to build a pipeline that supports the Trace Analytics OpenSearch Dashboards plugin. This pipeline takes data from the OpenTelemetry Collector and uses two other pipelines as sinks. These two separate pipelines index trace and the service map documents for the dashboard plugin.
Starting from Data Prepper 2.0, Data Prepper no longer supports otel_trace_raw_prepper processor due to the Data Prepper internal data model evolution. Instead, users should use otel_trace_raw.
entry-pipeline:
delay: "100"
source:
otel_trace_source:
ssl: false
buffer:
bounded_blocking:
buffer_size: 10240
batch_size: 160
sink:
- pipeline:
name: "raw-pipeline"
- pipeline:
name: "service-map-pipeline"
raw-pipeline:
source:
pipeline:
name: "entry-pipeline"
buffer:
bounded_blocking:
buffer_size: 10240
batch_size: 160
processor:
- otel_trace_raw:
sink:
- opensearch:
hosts: ["https://localhost:9200"]
insecure: true
username: admin
password: admin
index_type: trace-analytics-raw
service-map-pipeline:
delay: "100"
source:
pipeline:
name: "entry-pipeline"
buffer:
bounded_blocking:
buffer_size: 10240
batch_size: 160
processor:
- service_map_stateful:
sink:
- opensearch:
hosts: ["https://localhost:9200"]
insecure: true
username: admin
password: admin
index_type: trace-analytics-service-map
To maintain similar ingestion throughput and latency, scale the buffer_size and batch_size by the estimated maximum batch size in the client request payload.
Metrics pipeline
Data Prepper supports metrics ingestion using OTel. It currently supports the following metric types:
- Gauge
- Sum
- Summary
- Histogram
Other types are not supported. Data Prepper drops all other types, including Exponential Histogram and Summary. Additionally, Data Prepper does not support Scope instrumentation.
To set up a metrics pipeline:
metrics-pipeline:
source:
otel_metrics_source:
processor:
- otel_metrics_raw_processor:
sink:
- opensearch:
hosts: ["https://localhost:9200"]
username: admin
password: admin
S3 log ingestion pipeline
The following example demonstrates how to use the S3Source and Grok Processor plugins to process unstructured log data from Amazon Simple Storage Service (Amazon S3). This example uses application load balancer logs. As the application load balancer writes logs to S3, S3 creates notifications in Amazon SQS. Data Prepper monitors those notifications and reads the S3 objects to get the log data and process it.
log-pipeline:
source:
s3:
notification_type: "sqs"
compression: "gzip"
codec:
newline:
sqs:
queue_url: "https://sqs.us-east-1.amazonaws.com/12345678910/ApplicationLoadBalancer"
aws:
region: "us-east-1"
sts_role_arn: "arn:aws:iam::12345678910:role/Data-Prepper"
processor:
- grok:
match:
message: ["%{DATA:type} %{TIMESTAMP_ISO8601:time} %{DATA:elb} %{DATA:client} %{DATA:target} %{BASE10NUM:request_processing_time} %{DATA:target_processing_time} %{BASE10NUM:response_processing_time} %{BASE10NUM:elb_status_code} %{DATA:target_status_code} %{BASE10NUM:received_bytes} %{BASE10NUM:sent_bytes} \"%{DATA:request}\" \"%{DATA:user_agent}\" %{DATA:ssl_cipher} %{DATA:ssl_protocol} %{DATA:target_group_arn} \"%{DATA:trace_id}\" \"%{DATA:domain_name}\" \"%{DATA:chosen_cert_arn}\" %{DATA:matched_rule_priority} %{TIMESTAMP_ISO8601:request_creation_time} \"%{DATA:actions_executed}\" \"%{DATA:redirect_url}\" \"%{DATA:error_reason}\" \"%{DATA:target_list}\" \"%{DATA:target_status_code_list}\" \"%{DATA:classification}\" \"%{DATA:classification_reason}"]
- grok:
match:
request: ["(%{NOTSPACE:http_method})? (%{NOTSPACE:http_uri})? (%{NOTSPACE:http_version})?"]
- grok:
match:
http_uri: ["(%{WORD:protocol})?(://)?(%{IPORHOST:domain})?(:)?(%{INT:http_port})?(%{GREEDYDATA:request_uri})?"]
- date:
from_time_received: true
destination: "@timestamp"
sink:
- opensearch:
hosts: [ "https://localhost:9200" ]
username: "admin"
password: "admin"
index: alb_logs
Migrating from Logstash
Data Prepper supports Logstash configuration files for a limited set of plugins. Simply use the logstash config to run Data Prepper.
docker run --name data-prepper \
-v /full/path/to/logstash.conf:/usr/share/data-prepper/pipelines/pipelines.conf \
opensearchproject/opensearch-data-prepper:latest
This feature is limited by feature parity of Data Prepper. As of Data Prepper 1.2 release, the following plugins from the Logstash configuration are supported:
- HTTP Input plugin
- Grok Filter plugin
- Elasticsearch Output plugin
- Amazon Elasticsearch Output plugin
Configure the Data Prepper server
Data Prepper itself provides administrative HTTP endpoints such as /list to list pipelines and /metrics/prometheus to provide Prometheus-compatible metrics data. The port that has these endpoints has a TLS configuration and is specified by a separate YAML file. By default, these endpoints are secured by Data Prepper docker images. We strongly recommend providing your own configuration file for securing production environments. Here is an example data-prepper-config.yaml:
ssl: true
keyStoreFilePath: "/usr/share/data-prepper/keystore.jks"
keyStorePassword: "password"
privateKeyPassword: "other_password"
serverPort: 1234
To configure the Data Prepper server, run Data Prepper with the additional yaml file.
docker run --name data-prepper \
-v /full/path/to/my-pipelines.yaml:/usr/share/data-prepper/pipelines/my-pipelines.yaml \
-v /full/path/to/data-prepper-config.yaml:/usr/share/data-prepper/data-prepper-config.yaml \
opensearchproject/data-prepper:latest
Configure peer forwarder
Data Prepper provides an HTTP service to forward events between Data Prepper nodes for aggregation. This is required for operating Data Prepper in a clustered deployment. Currently, peer forwarding is supported in aggregate, service_map_stateful, and otel_trace_raw processors. Peer forwarder groups events based on the identification keys provided by the processors. For service_map_stateful and otel_trace_raw it’s traceId by default and can not be configured. For aggregate processor, it is configurable using identification_keys option.
Peer forwarder supports peer discovery through one of three options: a static list, a DNS record lookup , or AWS Cloud Map. Peer discovery can be configured using discovery_mode option. Peer forwarder also supports SSL for verification and encryption, and mTLS for mutual authentication in a peer forwarding service.
To configure peer forwarder, add configuration options to data-prepper-config.yaml mentioned in the Configure the Data Prepper server section:
peer_forwarder:
discovery_mode: dns
domain_name: "data-prepper-cluster.my-domain.net"
ssl: true
ssl_certificate_file: "<cert-file-path>"
ssl_key_file: "<private-key-file-path>"
authentication:
mutual_tls:
Pipeline Configurations
Since Data Prepper 2.5, shared pipeline components can be configured under the reserved section pipeline_configurations when all pipelines are defined in a single pipeline configuration YAML file. Shared pipeline configurations can include certain components within Extension Plugins, as shown in the following example that refers to secrets configurations for an opensearch sink:
pipeline_configurations:
aws:
secrets:
credential-secret-config:
secret_id: <YOUR_SECRET_ID>
region: <YOUR_REGION>
sts_role_arn: <YOUR_STS_ROLE_ARN>
simple-sample-pipeline:
...
sink:
- opensearch:
hosts: [ "${{aws_secrets:host-secret-config}}" ]
username: "${{aws_secrets:credential-secret-config:username}}"
password: "${{aws_secrets:credential-secret-config:password}}"
index: "test-migration"
When the same component is defined in both pipelines.yaml and data-prepper-config.yaml, the definition in the pipelines.yaml will overwrite the counterpart in data-prepper-config.yaml. For more information on shared pipeline components, see AWS secrets extension plugin for details.