Star-tree index
This is an experimental feature and is not recommended for use in a production environment. For updates on the progress of the feature or if you want to leave feedback, join the discussion on the OpenSearch forum.
A star-tree index is a multi-field index that improves the performance of aggregations.
OpenSearch will automatically use a star-tree index to optimize aggregations if the queried fields are part of dimension fields and the aggregations are on star-tree metric fields. No changes are required in the query syntax or the request parameters.
When to use a star-tree index
A star-tree index can be used to perform faster aggregations. Consider the following criteria and features when deciding to use a star-tree index:
- Star-tree indexes natively support multi-field aggregations.
- Star-tree indexes are created in real time as part of the indexing process, so the data in a star-tree will always be up to date.
- A star-tree index consolidates data, increasing index paging efficiency and using less IO for search queries.
Limitations
Star-tree indexes have the following limitations:
- A star-tree index should only be enabled on indexes whose data is not updated or deleted because updates and deletions are not accounted for in a star-tree index. To enforce this policy and use star-tree indexes, set the
index.append_only.enabledsetting totrue. - A star-tree index can be used for aggregation queries only if the queried fields are a subset of the star-tree’s dimensions and the aggregated fields are a subset of the star-tree’s metrics.
- After a star-tree index is enabled, it cannot be disabled. In order to disable a star-tree index, the data in the index must be reindexed without the star-tree mapping. Furthermore, changing a star-tree configuration will also require a reindex operation.
- Multi-values/array values are not supported.
- Only limited queries and aggregations are supported. Support for more features will be added in future versions.
- The cardinality of the dimensions should not be very high (as with
_idfields). Higher cardinality leads to increased storage usage and query latency.
Star-tree index structure
The following image illustrates a standard star-tree index structure.
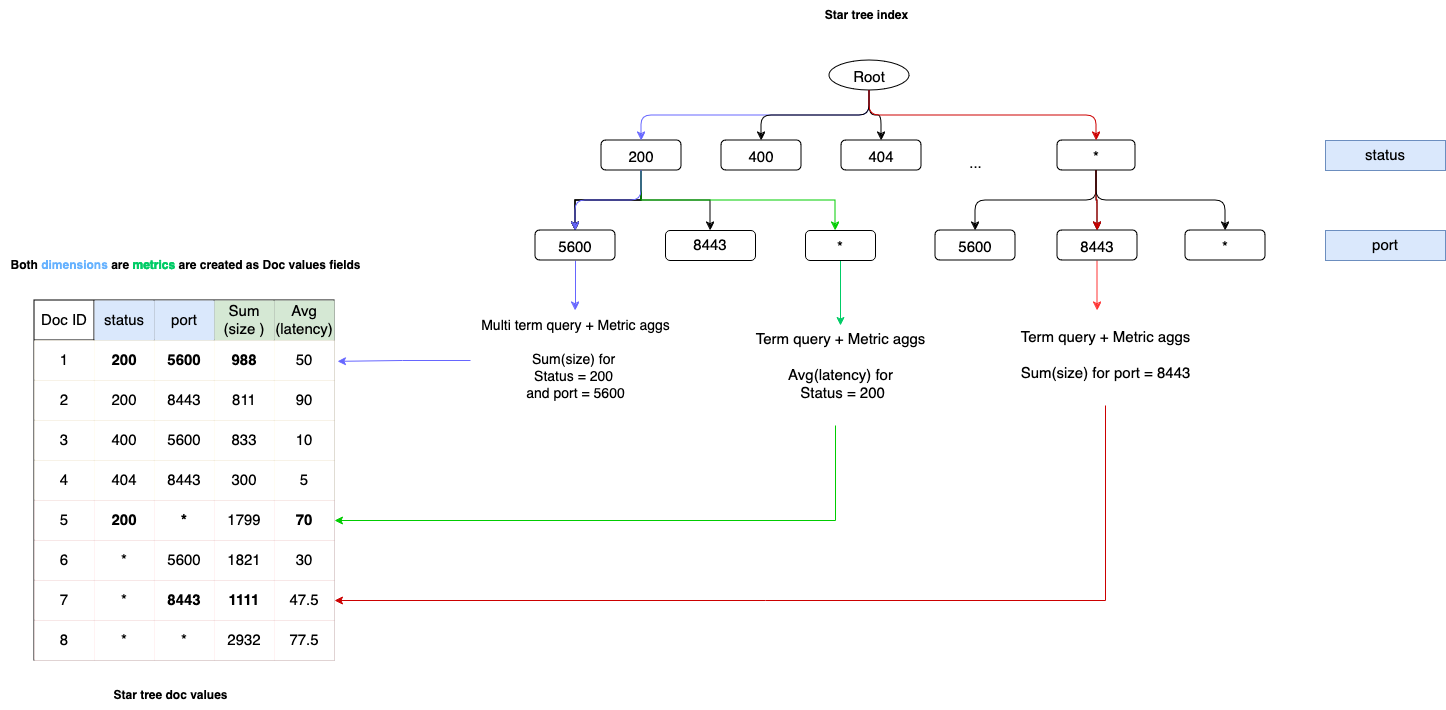
Sorted and aggregated star-tree documents are backed by doc_values in an index. The columnar data found in doc_values is stored using the following properties:
- The values are sorted based on the fields set in the
ordered_dimensionsetting. In the preceding image, the dimensions are determined by thestatussetting and then by theportfor each status. - For each unique dimension/value combination, the aggregated values for all the metrics, such as
avg(size)andcount(requests), are precomputed during ingestion.
Leaf nodes
Each node in a star-tree index points to a range of star-tree documents. Nodes can be further split into child nodes based on the max_leaf_docs configuration. The number of documents that a leaf node points to is less than or equal to the value set in max_leaf_docs. This ensures that the maximum number of documents that need to traverse nodes to derive an aggregated value is at most the number of max_leaf_docs, which provides predictable latency.
Star nodes
A star node contains the aggregated data of all the other nodes for a particular dimension, acting as a “catch-all” node. When a star node is found in a dimension, that dimension is skipped during aggregation. This groups together all values of that dimension and allows a query to skip non-competitive nodes when fetching the aggregated value of a particular field.
The star-tree index structure diagram contains the following three examples demonstrating how a query behaves when retrieving aggregations from nodes in the star-tree:
- Blue: In a
termsquery that searches for the average request size aggregation, theportequals8443and the status equals200. Because the query contains values in both thestatusandportdimensions, the query traverses status node200and returns the aggregations from child node8443. - Green: In a
termquery that searches for the number of aggregation requests, thestatusequals200. Because the query only contains a value from thestatusdimension, the query traverses the200node’s child star node, which contains the aggregated value of all theportchild nodes. - Red: In a
termquery that searches for the average request size aggregation, the port equals5600. Because the query does not contain a value from thestatusdimension, the query traverses a star node and returns the aggregated result from the5600child node.
Support for the Terms query will be added in a future version. For more information, see GitHub issue #15257.
Enabling a star-tree index
To use a star-tree index, modify the following settings:
- Set the feature flag
opensearch.experimental.feature.composite_index.star_tree.enabledtotrue. For more information about enabling and disabling feature flags, see Enabling experimental features. - Set the
indices.composite_index.star_tree.enabledsetting totrue. For instructions on how to configure OpenSearch, see Configuring settings. - Set the
index.composite_indexindex setting totrueduring index creation. - Set the
index.append_only.enabledindex setting totrueduring index creation. - Ensure that the
doc_valuesparameter is enabled for thedimensionsandmetricsfields used in your star-tree mapping.
Example mapping
In the following example, index mappings define the star-tree configuration. The star-tree index precomputes aggregations in the logs index. The aggregations are calculated on the size and latency fields for all the combinations of values indexed in the port and status fields:
PUT logs
{
"settings": {
"index.number_of_shards": 1,
"index.number_of_replicas": 0,
"index.composite_index": true,
"index.append_only.enabled": true
},
"mappings": {
"composite": {
"request_aggs": {
"type": "star_tree",
"config": {
"date_dimension" : {
"name": "@timestamp",
"calendar_intervals": [
"month",
"day"
]
},
"ordered_dimensions": [
{
"name": "status"
},
{
"name": "port"
},
{
"name": "method"
}
],
"metrics": [
{
"name": "size",
"stats": [
"sum"
]
},
{
"name": "latency",
"stats": [
"avg"
]
}
]
}
}
},
"properties": {
"status": {
"type": "integer"
},
"port": {
"type": "integer"
},
"size": {
"type": "integer"
},
"method" : {
"type": "keyword"
},
"latency": {
"type": "scaled_float",
"scaling_factor": 10
}
}
}
}
For detailed information about star-tree index mappings and parameters, see Star-tree field type.
Supported queries and aggregations
Star-tree indexes can be used to optimize queries and aggregations.
Supported queries
The following queries are supported as of OpenSearch 2.19:
To use a query with a star-tree index, the query’s fields must be present in the ordered_dimensions section of the star-tree configuration. Queries must also be paired with a supported aggregation. Queries without aggregations cannot be used with a star-tree index. Currently, queries on date fields are not supported and will be added in later versions.
Supported aggregations
The following aggregations are supported by star-tree indexes.
Metric aggregations
The following metric aggregations are supported as of OpenSearch 2.18:
To use searchable aggregations with a star-tree index, make sure you fulfill the following prerequisites:
- The fields must be present in the
metricssection of the star-tree configuration. - The metric aggregation type must be part of the
statsparameter.
The following example gets the sum of all the values in the size field for all error logs with status=500, using the example mapping:
POST /logs/_search
{
"query": {
"term": {
"status": "500"
}
},
"aggs": {
"sum_size": {
"sum": {
"field": "size"
}
}
}
}
Using a star-tree index, the result will be retrieved from a single aggregated document as it traverses the status=500 node, as opposed to scanning through all of the matching documents. This results in lower query latency.
Date histograms with metric aggregations
You can use date histograms on calendar intervals with metric sub-aggregations.
To use date histogram aggregations and make them searchable in a star-tree index, remember the following requirements:
- The calendar intervals in a star-tree mapping configuration can use either the request’s calendar field or a field of lower granularity than the request field. For example, if an aggregation uses the
monthfield, the star-tree search can still use lower-granularity fields such asday. - A metric sub-aggregation must be part of the aggregation request.
The following example filters logs to include only those with status codes between 200 and 400 and sets the size of the response to 0, so that only aggregated results are returned. It then aggregates the filtered logs by calendar month and calculates the total size of the requests for each month:
POST /logs/_search
{
"size": 0,
"query": {
"range": {
"status": {
"gte": "200",
"lte": "400"
}
}
},
"aggs": {
"by_month": {
"date_histogram": {
"field": "@timestamp",
"calendar_interval": "month"
},
"aggs": {
"sum_size": {
"sum": {
"field": "size"
}
}
}
}
}
}
Using queries without a star-tree index
Set the indices.composite_index.star_tree.enabled setting to false to run queries without using a star-tree index.