Function score query
Use a function_score query if you need to alter the relevance scores of documents returned in the results. A function_score query defines a query and one or more functions that can be applied to all results or subsets of the results to recalculate their relevance scores.
Using one scoring function
The most basic example of a function_score query uses one function to recalculate the score. The following query uses a weight function to double all relevance scores. This function applies to all documents in the results because there is no query parameter specified within function_score:
GET shakespeare/_search
{
"query": {
"function_score": {
"weight": "2"
}
}
}
Applying the scoring function to a subset of documents
To apply the scoring function to a subset of documents, provide a query within the function:
GET shakespeare/_search
{
"query": {
"function_score": {
"query": {
"match": {
"play_name": "Hamlet"
}
},
"weight": "2"
}
}
}
Supported functions
The function_score query type supports the following functions:
- Built-in:
weight: Multiplies a document score by a predefined boost factor.random_score: Provides a random score that is consistent for a single user but different between users.field_value_factor: Uses the value of the specified document field to recalculate the score.- Decay functions (
gauss,exp, andlinear): Recalculates the score using a specified decay function.
- Custom:
script_score: Uses a script to score documents.
The weight function
When you use the weight function, the original relevance score is multiplied by the floating-point value of weight:
GET shakespeare/_search
{
"query": {
"function_score": {
"weight": "2"
}
}
}
Unlike the boost value, the weight function is not normalized.
The random score function
The random_score function provides a random score that is consistent for a single user but different between users. The score is a floating-point number in the [0, 1) range. By default, the random_score function uses internal Lucene document IDs as seed values, making random values irreproducible because documents can be renumbered after merges. To achieve consistency in generating random values, you can provide seed and field parameters. The field must be a field for which fielddata is enabled (commonly, a numeric field). The score is calculated using the seed, the fielddata values for the field, and a salt calculated using the index name and shard ID. Because the index name and shard ID are the same for documents that reside in the same shard, documents with the same field values will be assigned the same score. To ensure different scores for all documents in the same shard, use a field that has unique values for all documents. One option is to use the _seq_no field. However, if you choose this field, the scores can change if the document is updated because of the corresponding _seq_no update.
The following query uses the random_score function with a seed and field:
GET blogs/_search
{
"query": {
"function_score": {
"random_score": {
"seed": 20,
"field": "_seq_no"
}
}
}
}
The field value factor function
The field_value_factor function recalculates the score using the value of the specified document field. If the field is a multi-valued field, only its first value is used for calculations, and the others are not considered.
The field_value_factor function supports the following options:
-
field: The field to use in score calculations. -
factor: An optional factor by which the field value is multiplied. Default is 1. -
modifier: One of the modifiers to apply to the field value \(v\). The following table lists all supported modifiers.Modifier Formula Description log\(\log v\) Take the base-10 logarithm of the value. Taking a logarithm of a non-positive number is an illegal operation and will result in an error. For values between 0 (exclusive) and 1 (inclusive), this function returns non-negative values that will result in an error. We recommend using log1porlog2pinstead oflog.log1p\(\log (1 + v)\) Take the base-10 logarithm of the sum of 1 and the value. log2p\(\log (2 + v)\) Take the base-10 logarithm of the sum of 2 and the value. ln\(\ln v\) Take the natural logarithm of the value. Taking a logarithm of a non-positive number is an illegal operation and will result in an error. For values between 0 (exclusive) and 1 (inclusive), this function returns non-negative values that will result in an error. We recommend using ln1porln2pinstead ofln.ln1p\(\ln (1 + v)\) Take the natural logarithm of the sum of 1 and the value. ln2p\(\ln (2 + v)\) Take the natural logarithm of the sum of 2 and the value. reciprocal\(\frac {1}{v}\) Take the reciprocal of the value. square\(v^2\) Square the value. sqrt\(\sqrt v\) Take the square root of the value. Taking a square root of a negative number is an illegal operation and will result in an error. Ensure that \(v\) is non-negative. noneN/A Do not apply any modifier. -
missing: The value to use if the field is missing from the document. Thefactorandmodifierare applied to this value instead of the missing field value.
For example, the following query uses the field_value_factor function to give more weight to the views field:
GET blogs/_search
{
"query": {
"function_score": {
"field_value_factor": {
"field": "views",
"factor": 1.5,
"modifier": "log1p",
"missing": 1
}
}
}
}
The preceding query calculates the relevance score using the following formula:
\[\text{score} = \text{original score} \cdot \log(1 + 1.5 \cdot \text{views})\]The script score function
Using the script_score function, you can write a custom script for scoring documents, optionally incorporating values of fields in the document. The original relevance score is accessible in the _score variable.
The calculated score cannot be negative. A negative score will result in an error. Document scores have positive 32-bit floating-point values. A score with greater precision is converted to the nearest 32-bit floating-point number.
For example, the following query uses the script_score function to calculate the score based on the original score and the number of views and likes for the blog post. To give the number of views and likes a lesser weight, this formula takes the logarithm of the sum of views and likes. To make the logarithm valid even if the number of views and likes is 0, 1 is added to their sum:
GET blogs/_search
{
"query": {
"function_score": {
"query": {"match": {"name": "opensearch"}},
"script_score": {
"script": "_score * Math.log(1 + doc['likes'].value + doc['views'].value)"
}
}
}
}
Scripts are compiled and cached for faster performance. Thus, it’s preferable to reuse the same script and pass any parameters that the script needs:
GET blogs/_search
{
"query": {
"function_score": {
"query": {
"match": { "name": "opensearch" }
},
"script_score": {
"script": {
"params": {
"add": 1
},
"source": "_score * Math.log(params.add + doc['likes'].value + doc['views'].value)"
}
}
}
}
}
Decay functions
For many applications, you need to sort the results based on proximity or recency. You can do this with decay functions. Decay functions calculate a document score using one of three decay curves: Gaussian, exponential, or linear.
Decay functions operate only on numeric, date, and geopoint fields.
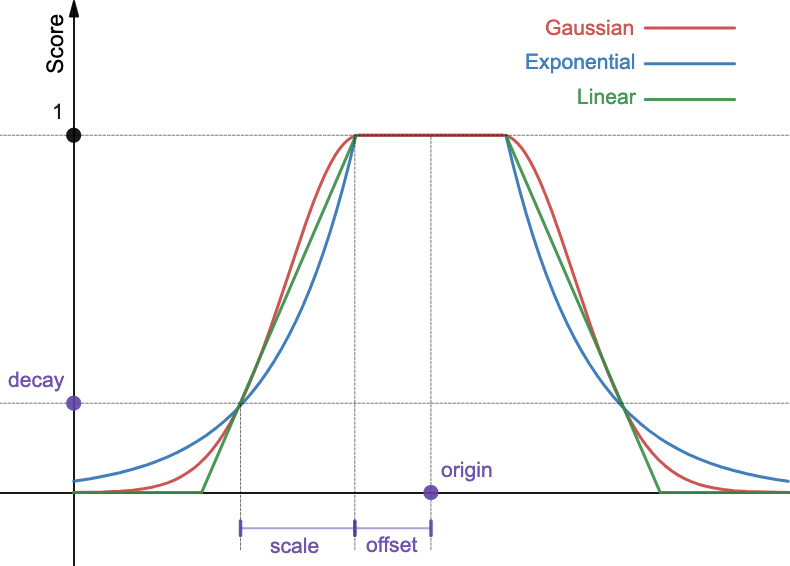
Decay functions calculate scores based on the origin, scale, offset, and decay, as shown in the following figure.
Example: Geopoint fields
Suppose you’re looking for a hotel near your office. You create a hotels index that maps the location field as a geopoint:
PUT hotels
{
"mappings": {
"properties": {
"location": {
"type": "geo_point"
}
}
}
}
You index two documents that correspond to nearby hotels:
PUT hotels/_doc/1
{
"name": "Hotel Within 200",
"location": {
"lat": 40.7105,
"lon": 74.00
}
}
PUT hotels/_doc/2
{
"name": "Hotel Outside 500",
"location": {
"lat": 40.7115,
"lon": 74.00
}
}
The origin defines the point from which the distance is calculated (the office location). The offset specifies the distance from the origin within which documents are given a full score of 1. You can give hotels within 200 ft of the office the same highest score. The scale defines the decay rate of the graph, and the decay defines the score to assign to a document at the scale + offset distance from the origin. Once you are outside the 200 ft radius, you may decide that if you have to walk another 300 ft to get to a hotel (scale = 300 ft), you’ll assign it one quarter of the original score (decay = 0.25).
You create the following query with the origin at (74.00, 40.71):
GET hotels/_search
{
"query": {
"function_score": {
"functions": [
{
"exp": {
"location": {
"origin": "40.71,74.00",
"offset": "200ft",
"scale": "300ft",
"decay": 0.25
}
}
}
]
}
}
}
The response contains both hotels. The hotel within 200 ft of the office has a score of 1, and the hotel outside of the 500 ft radius has a score 0.20, which is less than the decay parameter 0.25:
Response
{
"took": 854,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "hotels",
"_id": "1",
"_score": 1,
"_source": {
"name": "Hotel Within 200",
"location": {
"lat": 40.7105,
"lon": 74
}
}
},
{
"_index": "hotels",
"_id": "2",
"_score": 0.20099315,
"_source": {
"name": "Hotel Outside 500",
"location": {
"lat": 40.7115,
"lon": 74
}
}
}
]
}
}
Parameters
The following table lists all parameters supported by the gauss, exp, and linear functions.
| Parameter | Description |
|---|---|
origin | The point from which to calculate the distance. Must be provided as a number for numeric fields, a date for date fields, or a geopoint for geopoint fields. Required for geopoint and numeric fields. Optional for date fields (defaults to now). For date fields, date math is supported (for example, now-2d). |
offset | Defines the distance from the origin within which documents are given a score of 1. Optional. Default is 0. |
scale | Documents at the distance of scale + offset from the origin are assigned a score of decay. Required. For numeric fields, scale can be any number. For date fields, scale can be defined as a number with units (5h, 1d). If units are not provided, scale defaults to milliseconds. For geopoint fields, scale can be defined as a number with units (1mi, 5km). If units are not provided, scale defaults to meters. |
decay | Defines the score of a document at the distance of scale + offset from the origin. Optional. Default is 0.5. |
For fields that are missing from the document, decay functions return a score of 1.
Example: Numeric fields
The following query uses the exponential decay function to prioritize blog posts by the number of comments:
GET blogs/_search
{
"query": {
"function_score": {
"functions": [
{
"exp": {
"comments": {
"origin": "20",
"offset": "5",
"scale": "10"
}
}
}
]
}
}
}
The first two blog posts in the results have a score of 1 because one is at the origin (20) and the other is at a distance of 16, which is within the offset (the range within which documents receive a full score is calculated as 20 \(\pm\) 5 and is [15, 25]). The third blog post is at a distance of scale + offset from the origin (20 − (5 + 10) = 15), so it’s given the default decay score (0.5):
Response
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 4,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "blogs",
"_id": "1",
"_score": 1,
"_source": {
"name": "Semantic search in OpenSearch",
"views": 1200,
"likes": 150,
"comments": 16,
"date_posted": "2022-04-17"
}
},
{
"_index": "blogs",
"_id": "2",
"_score": 1,
"_source": {
"name": "Get started with OpenSearch 2.7",
"views": 1400,
"likes": 100,
"comments": 20,
"date_posted": "2022-05-02"
}
},
{
"_index": "blogs",
"_id": "3",
"_score": 0.5,
"_source": {
"name": "Distributed tracing with Data Prepper",
"views": 800,
"likes": 50,
"comments": 5,
"date_posted": "2022-04-25"
}
},
{
"_index": "blogs",
"_id": "4",
"_score": 0.4352753,
"_source": {
"name": "A very old blog",
"views": 100,
"likes": 20,
"comments": 3,
"date_posted": "2000-04-25"
}
}
]
}
}
Example: Date fields
The following query uses the Gaussian decay function to prioritize blog posts published around 04/24/2002:
GET blogs/_search
{
"query": {
"function_score": {
"functions": [
{
"gauss": {
"date_posted": {
"origin": "2022-04-24",
"offset": "1d",
"scale": "6d",
"decay": 0.25
}
}
}
]
}
}
}
In the results, the first blog post was published within one day of 04/24/2022, so it has the highest score of 1. The second blog post was published on 04/17/2022, which is within offset + scale (1d + 6d) and therefore has a score equal to decay (0.25). The third blog post was published more than 7 days after 04/24/2022, so it has a lower score. The last blog post has a score of 0 because it was published years ago:
Response
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 4,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "blogs",
"_id": "3",
"_score": 1,
"_source": {
"name": "Distributed tracing with Data Prepper",
"views": 800,
"likes": 50,
"comments": 5,
"date_posted": "2022-04-25"
}
},
{
"_index": "blogs",
"_id": "1",
"_score": 0.25,
"_source": {
"name": "Semantic search in OpenSearch",
"views": 1200,
"likes": 150,
"comments": 16,
"date_posted": "2022-04-17"
}
},
{
"_index": "blogs",
"_id": "2",
"_score": 0.15154076,
"_source": {
"name": "Get started with OpenSearch 2.7",
"views": 1400,
"likes": 100,
"comments": 20,
"date_posted": "2022-05-02"
}
},
{
"_index": "blogs",
"_id": "4",
"_score": 0,
"_source": {
"name": "A very old blog",
"views": 100,
"likes": 20,
"comments": 3,
"date_posted": "2000-04-25"
}
}
]
}
}
Multi-valued fields
If the field that you specify for decay calculation contains multiple values, you can use the multi_value_mode parameter. This parameter specifies one of the following functions to determine the field value that is used for calculations:
min: (Default) The minimum distance from theorigin.max: The maximum distance from theorigin.avg: The average distance from theorigin.sum: The sum of all distances from theorigin.
For example, you index a document with an array of distances:
PUT testindex/_doc/1
{
"distances": [1, 2, 3, 4, 5]
}
The following query uses the max distance of a multi-valued field distances to calculate decay:
GET testindex/_search
{
"query": {
"function_score": {
"functions": [
{
"exp": {
"distances": {
"origin": "6",
"offset": "5",
"scale": "1"
},
"multi_value_mode": "max"
}
}
]
}
}
}
The document is given a score of 1 because the maximum distance from the origin (1) is within the offset from the origin:
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "testindex",
"_id": "1",
"_score": 1,
"_source": {
"distances": [
1,
2,
3,
4,
5
]
}
}
]
}
}
Decay curve calculation
The following formulas define score computation for various decay functions (\(v\) denotes the document field value).
Gaussian
\[\text{score} = \exp \left(-\frac {(\max(0, \lvert v - \text{origin} \rvert - \text{offset}))^2} {2\sigma^2} \right),\]where \(\sigma\) is calculated to ensure that the score is equal to decay at the distance offset + scale from the origin:
Exponential
\[\text{score} = \exp (\lambda \cdot \max(0, \lvert v - \text{origin} \rvert - \text{offset})),\]where \(\lambda\) is calculated to ensure that the score is equal to decay at the distance offset + scale from the origin:
Linear
\[\text{score} = \max \left(\frac {s - \max(0, \lvert v - \text{origin} \rvert - \text{offset})} {s} \right),\]where \(s\) is calculated to ensure that the score is equal to decay at the distance offset + scale from the origin:
Using multiple scoring functions
You can specify multiple scoring functions in a function score query by listing them in the functions array.
Combining scores from multiple functions
Different functions can use different scales for scoring. For example, the random_score function provides a score between 0 and 1, but the field_value_factor does not have a specific scale for the score. Additionally, you may want to weigh scores given by different functions differently. To adjust scores for different functions, you can specify the weight parameter for each function. The score given by each function is then multiplied by the weight to produce the final score for that function. The weight parameter must be provided in the functions array in order to differentiate it from the weight function,
The scores given by each function are combined using the score_mode parameter, which takes one of the following values:
multiply: (Default) Scores are multiplied.sum: Scores are added.avg: Scores are averaged. Ifweightis specified, this is a weighted average. For example, if the first function with the weight \(1\) returns the score \(10\), and the second function with the weight \(4\) returns the score \(20\), the average is calculated as \(\frac {10 \cdot 1 + 20 \cdot 4}{1 + 4} = 18\).first: The score from the first function that has a matching filter is taken.max: The maximum score is taken.min: The minimum score is taken.
Specifying an upper limit for a score
You can specify an upper limit for a function score in the max_boost parameter. The default upper limit is the maximum magnitude for a float value: (2 − 2−23) · 2127.
Combining the score for all functions with the query score
You can specify how the score computed using all functions is combined with the query score in the boost_mode parameter, which takes one of the following values:
multiply: (Default) Multiply the query score by the function score.replace: Ignore the query score and use the function score.sum: Add the query score and the function score.avg: Average the query score and the function score.max: Take the greater of the query score and the function score.min: Take the lesser of the query score and the function score.
Filtering documents that don’t meet a threshold
Changing the relevance score does not change the list of matching documents. To exclude some documents that don’t meet a threshold, specify the threshold value in the min_score parameter. All documents returned by the query are then scored and filtered using the threshold value.
Example
The following request searches for blog posts that include the words “OpenSearch Data Prepper”, preferring the posts published around 04/24/2022. Additionally, the number of views and likes are taken into consideration. Finally, the cutoff threshold is set at the score of 10:
GET blogs/_search
{
"query": {
"function_score": {
"boost": "5",
"functions": [
{
"gauss": {
"date_posted": {
"origin": "2022-04-24",
"offset": "1d",
"scale": "6d"
}
},
"weight": 1
},
{
"gauss": {
"likes": {
"origin": 200,
"scale": 200
}
},
"weight": 4
},
{
"gauss": {
"views": {
"origin": 1000,
"scale": 800
}
},
"weight": 2
}
],
"query": {
"match": {
"name": "opensearch data prepper"
}
},
"max_boost": 10,
"score_mode": "max",
"boost_mode": "multiply",
"min_score": 10
}
}
}
The results contain the three matching blog posts:
Response
{
"took": 14,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 3,
"relation": "eq"
},
"max_score": 31.191923,
"hits": [
{
"_index": "blogs",
"_id": "3",
"_score": 31.191923,
"_source": {
"name": "Distributed tracing with Data Prepper",
"views": 800,
"likes": 50,
"comments": 5,
"date_posted": "2022-04-25"
}
},
{
"_index": "blogs",
"_id": "1",
"_score": 13.907352,
"_source": {
"name": "Semantic search in OpenSearch",
"views": 1200,
"likes": 150,
"comments": 16,
"date_posted": "2022-04-17"
}
},
{
"_index": "blogs",
"_id": "2",
"_score": 11.150461,
"_source": {
"name": "Get started with OpenSearch 2.7",
"views": 1400,
"likes": 100,
"comments": 20,
"date_posted": "2022-05-02"
}
}
]
}
}
Named functions
When defining a function, you can specify its name using the _name parameter at the top level. This name is useful for debugging and understanding the scoring process. Once specified, the function name is included in the score calculation explanation whenever possible (this applies to functions, filters, and queries). You can identify the function by its _name in the response.
Example
The following request sets explain to true for debugging purposes in order to obtain a scoring explanation in the response. Each function contains a _name parameter so that you can identify the function unambiguously:
GET blogs/_search
{
"explain": true,
"size": 1,
"query": {
"function_score": {
"functions": [
{
"_name": "likes_function",
"script_score": {
"script": {
"lang": "painless",
"source": "return doc['likes'].value * 2;"
}
},
"weight": 0.6
},
{
"_name": "views_function",
"field_value_factor": {
"field": "views",
"factor": 1.5,
"modifier": "log1p",
"missing": 1
},
"weight": 0.3
},
{
"_name": "comments_function",
"gauss": {
"comments": {
"origin": 1000,
"scale": 800
}
},
"weight": 0.1
}
]
}
}
}
The response explains the scoring process. For each function, the explanation contains the function _name in its description:
Response
{
"took": 14,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 3,
"relation": "eq"
},
"max_score": 6.1600614,
"hits": [
{
"_shard": "[blogs][0]",
"_node": "_yndTaZHQWimcDgAfOfRtQ",
"_index": "blogs",
"_id": "1",
"_score": 6.1600614,
"_source": {
"name": "Semantic search in OpenSearch",
"views": 1200,
"likes": 150,
"comments": 16,
"date_posted": "2022-04-17"
},
"_explanation": {
"value": 6.1600614,
"description": "function score, product of:",
"details": [
{
"value": 1,
"description": "*:*",
"details": []
},
{
"value": 6.1600614,
"description": "min of:",
"details": [
{
"value": 6.1600614,
"description": "function score, score mode [multiply]",
"details": [
{
"value": 180,
"description": "product of:",
"details": [
{
"value": 300,
"description": "script score function(_name: likes_function), computed with script:\"Script{type=inline, lang='painless', idOrCode='return doc['likes'].value * 2;', options={}, params={}}\"",
"details": [
{
"value": 1,
"description": "_score: ",
"details": [
{
"value": 1,
"description": "*:*",
"details": []
}
]
}
]
},
{
"value": 0.6,
"description": "weight",
"details": []
}
]
},
{
"value": 0.9766541,
"description": "product of:",
"details": [
{
"value": 3.2555137,
"description": "field value function(_name: views_function): log1p(doc['views'].value?:1.0 * factor=1.5)",
"details": []
},
{
"value": 0.3,
"description": "weight",
"details": []
}
]
},
{
"value": 0.035040613,
"description": "product of:",
"details": [
{
"value": 0.35040614,
"description": "Function for field comments:",
"details": [
{
"value": 0.35040614,
"description": "exp(-0.5*pow(MIN[Math.max(Math.abs(16.0(=doc value) - 1000.0(=origin))) - 0.0(=offset), 0)],2.0)/461662.4130844683, _name: comments_function)",
"details": []
}
]
},
{
"value": 0.1,
"description": "weight",
"details": []
}
]
}
]
},
{
"value": 3.4028235e+38,
"description": "maxBoost",
"details": []
}
]
}
]
}
}
]
}
}