Vector search basics
Vector search, also known as similarity search or nearest neighbor search, is a powerful technique for finding items that are most similar to a given input. Use cases include semantic search to understand user intent, recommendations (for example, an “other songs you might like” feature in a music application), image recognition, and fraud detection. For more background information about vector search, see Nearest neighbor search.
Vector embeddings
Unlike traditional search methods that rely on exact keyword matches, vector search uses vector embeddings—numerical representations of data such as text, images, or audio. These embeddings are stored as multi-dimensional vectors, capturing deeper patterns and similarities in meaning, context, or structure. For example, a large language model (LLM) can create vector embeddings from input text, as shown in the following image.
Similarity search
A vector embedding is a vector in a high-dimensional space. Its position and orientation capture meaningful relationships between objects. Vector search finds the most similar results by comparing a query vector to stored vectors and returning the closest matches. OpenSearch uses the k-nearest neighbors (k-NN) algorithm to efficiently identify the most similar vectors. Unlike keyword search, which relies on exact word matches, vector search measures similarity based on distance in this high-dimensional space.
In the following image, the vectors for Wild West and Broncos are closer to each other, while both are far from Basketball, reflecting their semantic differences.
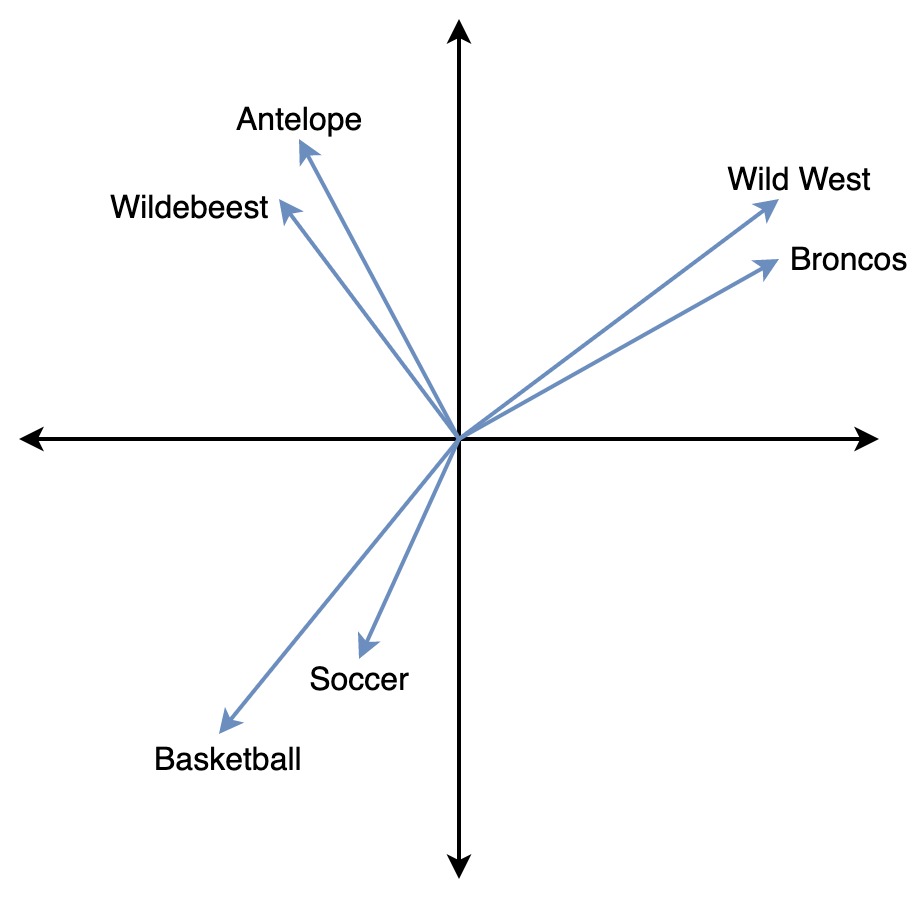
To learn more about the types of vector search that OpenSearch supports, see Vector search techniques.
Calculating similarity
Vector similarity measures how close two vectors are in a multi-dimensional space, facilitating tasks like nearest neighbor search and ranking results by relevance. OpenSearch supports multiple distance metrics (spaces) for calculating vector similarity:
- L1 (Manhattan distance): Sums the absolute differences between vector components.
- L2 (Euclidean distance): Calculates the square root of the sum of squared differences, making it sensitive to magnitude.
- L∞ (Chebyshev distance): Considers only the maximum absolute difference between corresponding vector elements.
- Cosine similarity: Measures the angle between vectors, focusing on direction rather than magnitude.
- Inner product: Determines similarity based on vector dot products, which can be useful for ranking.
- Hamming distance: Counts differing elements in binary vectors.
- Hamming bit: Applies the same principle as Hamming distance but is optimized for binary-encoded data.
To learn more about the distance metrics, see Spaces.