Semantic search using Amazon Bedrock Titan
This tutorial shows you how to implement semantic search in Amazon OpenSearch Service using the Amazon Bedrock Titan embedding model.
If you are using self-managed OpenSearch instead of Amazon OpenSearch Service, create a connector to the model on Amazon Bedrock using the blueprint. For more information about creating a connector, see Connectors.
The easiest way to set up an embedding model in Amazon OpenSearch Service is by using AWS CloudFormation. Alternatively, you can set up an embedding model using the AIConnectorHelper notebook.
Amazon Bedrock has a quota limit. For more information about increasing this limit, see Increase model invocation capacity with Provisioned Throughput in Amazon Bedrock.
Replace the placeholders beginning with the prefix your_ with your own values.
Prerequisite: Create an OpenSearch cluster
Go to the Amazon OpenSearch Service console and create an OpenSearch domain.
Note the domain Amazon Resource Name (ARN); you’ll use it in the following steps.
Step 1: Create an IAM role to invoke the model on Amazon Bedrock
To invoke the model on Amazon Bedrock, you must create an AWS Identity and Access Management (IAM) role with appropriate permissions. The connector will use this role to invoke the model.
Go to the IAM console, create a new IAM role named my_invoke_bedrock_role, and add the following trust policy and permissions:
- Custom trust policy:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "es.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}
- Permissions:
{
"Version": "2012-10-17",
"Statement": [
{
"Action": [
"bedrock:InvokeModel"
],
"Effect": "Allow",
"Resource": "arn:aws:bedrock:*::foundation-model/amazon.titan-embed-text-v1"
}
]
}
Note the role ARN; you’ll use it in the following steps.
Step 2: Configure an IAM role in OpenSearch
Follow these steps to configure an IAM role in Amazon OpenSearch Service.
Step 2.1: Create an IAM role for signing connector requests
Generate a new IAM role specifically for signing your Create Connector API request.
Create an IAM role named my_create_bedrock_connector_role with the following trust policy and permissions:
- Custom trust policy:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "your_iam_user_arn"
},
"Action": "sts:AssumeRole"
}
]
}
You’ll use the your_iam_user_arn IAM user to assume the role in Step 3.1.
- Permissions:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "iam:PassRole",
"Resource": "your_iam_role_arn_created_in_step1"
},
{
"Effect": "Allow",
"Action": "es:ESHttpPost",
"Resource": "your_opensearch_domain_arn_created"
}
]
}
Note this role ARN; you’ll use it in the following steps.
Step 2.2: Map a backend role
Follow these steps to map a backend role:
- Log in to OpenSearch Dashboards and select Security on the top menu.
- Select Roles, and then select the ml_full_access role.
- On the ml_full_access role details page, select Mapped users, and then select Manage mapping.
- Enter the IAM role ARN created in Step 2.1 in the Backend roles field, as shown in the following image.
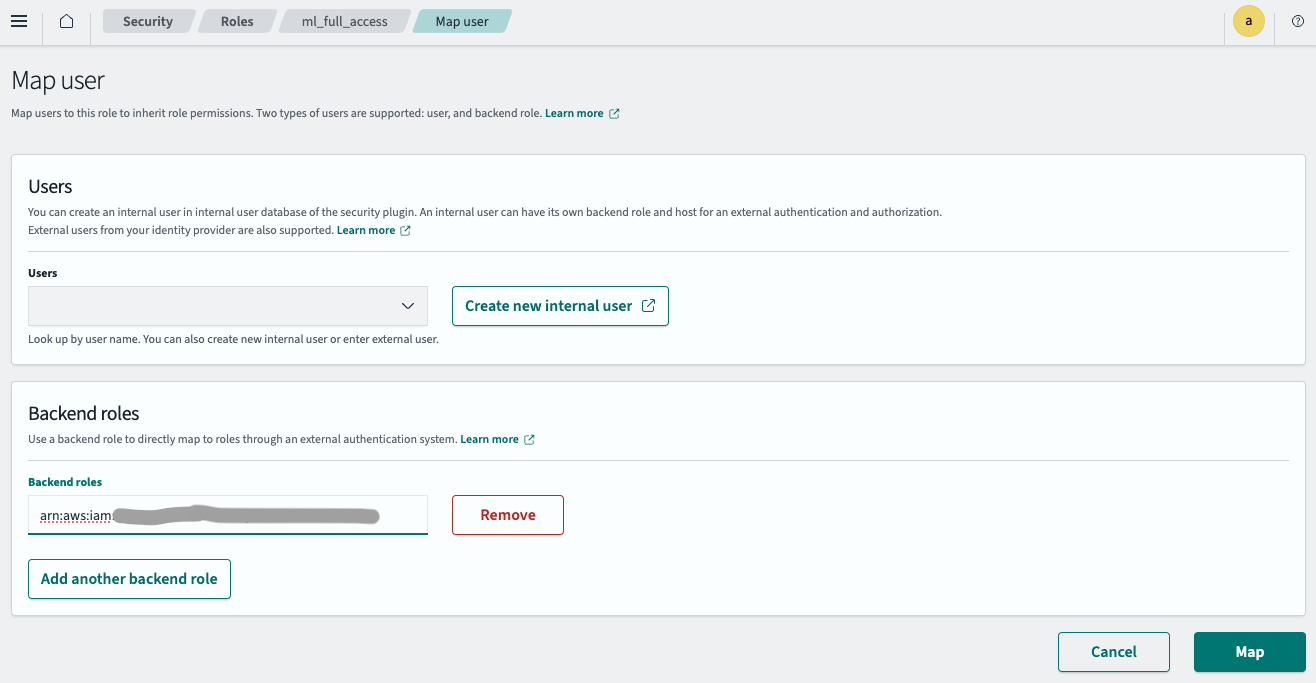
- Select Map.
The IAM role is now successfully configured in your OpenSearch cluster.
Step 3: Create a connector
Follow these steps to create a connector for the model. For more information about creating a connector, see Connectors.
Step 3.1: Get temporary credentials
Use the credentials of the IAM user specified in Step 2.1 to assume the role:
aws sts assume-role --role-arn your_iam_role_arn_created_in_step2.1 --role-session-name your_session_name
Copy the temporary credentials from the response and configure them in ~/.aws/credentials:
[default]
AWS_ACCESS_KEY_ID=your_access_key_of_role_created_in_step2.1
AWS_SECRET_ACCESS_KEY=your_secret_key_of_role_created_in_step2.1
AWS_SESSION_TOKEN=your_session_token_of_role_created_in_step2.1
Step 3.2: Create a connector
Run the following Python code with the temporary credentials configured in ~/.aws/credentials:
import boto3
import requests
from requests_aws4auth import AWS4Auth
host = 'your_amazon_opensearch_domain_endpoint_created'
region = 'your_amazon_opensearch_domain_region'
service = 'es'
credentials = boto3.Session().get_credentials()
awsauth = AWS4Auth(credentials.access_key, credentials.secret_key, region, service, session_token=credentials.token)
path = '/_plugins/_ml/connectors/_create'
url = host + path
payload = {
"name": "Amazon Bedrock Connector: titan embedding v1",
"description": "The connector to bedrock Titan embedding model",
"version": 1,
"protocol": "aws_sigv4",
"parameters": {
"region": "your_bedrock_model_region",
"service_name": "bedrock"
},
"credential": {
"roleArn": "your_iam_role_arn_created_in_step1"
},
"actions": [
{
"action_type": "predict",
"method": "POST",
"url": "https://bedrock-runtime.your_bedrock_model_region.amazonaws.com/model/amazon.titan-embed-text-v1/invoke",
"headers": {
"content-type": "application/json",
"x-amz-content-sha256": "required"
},
"request_body": "{ \"inputText\": \"${parameters.inputText}\" }",
"pre_process_function": "\n StringBuilder builder = new StringBuilder();\n builder.append(\"\\\"\");\n String first = params.text_docs[0];\n builder.append(first);\n builder.append(\"\\\"\");\n def parameters = \"{\" +\"\\\"inputText\\\":\" + builder + \"}\";\n return \"{\" +\"\\\"parameters\\\":\" + parameters + \"}\";",
"post_process_function": "\n def name = \"sentence_embedding\";\n def dataType = \"FLOAT32\";\n if (params.embedding == null || params.embedding.length == 0) {\n return params.message;\n }\n def shape = [params.embedding.length];\n def json = \"{\" +\n \"\\\"name\\\":\\\"\" + name + \"\\\",\" +\n \"\\\"data_type\\\":\\\"\" + dataType + \"\\\",\" +\n \"\\\"shape\\\":\" + shape + \",\" +\n \"\\\"data\\\":\" + params.embedding +\n \"}\";\n return json;\n "
}
]
}
headers = {"Content-Type": "application/json"}
r = requests.post(url, auth=awsauth, json=payload, headers=headers)
print(r.text)
The script outputs a connector ID:
{"connector_id":"1p0u8o0BWbTmLN9F2Y7m"}
Note the connector ID; you’ll use it in the next step.
Step 4: Create and test the model
Log in to OpenSearch Dashboards, open the DevTools console, and run the following requests to create and test the model.
-
Create a model group:
POST /_plugins/_ml/model_groups/_register { "name": "Bedrock_embedding_model", "description": "Test model group for bedrock embedding model" }The response contains the model group ID:
{ "model_group_id": "LxWiQY0BTaDH9c7t9xeE", "status": "CREATED" } -
Register the model:
POST /_plugins/_ml/models/_register { "name": "bedrock titan embedding model v1", "function_name": "remote", "description": "test embedding model", "model_group_id": "LxWiQY0BTaDH9c7t9xeE", "connector_id": "N0qpQY0BOhavBOmfOCnw" }The response contains the model ID:
{ "task_id": "O0q3QY0BOhavBOmf1SmL", "status": "CREATED", "model_id": "PEq3QY0BOhavBOmf1Sml" } -
Deploy the model:
POST /_plugins/_ml/models/PEq3QY0BOhavBOmf1Sml/_deployThe response contains a task ID for the deployment operation:
{ "task_id": "PUq4QY0BOhavBOmfBCkQ", "task_type": "DEPLOY_MODEL", "status": "COMPLETED" } -
Test the model:
POST /_plugins/_ml/models/PEq3QY0BOhavBOmf1Sml/_predict { "parameters": { "inputText": "hello world" } }The response contains the embeddings generated by the model:
{ "inference_results": [ { "output": [ { "name": "sentence_embedding", "data_type": "FLOAT32", "shape": [ 1536 ], "data": [ 0.7265625, -0.0703125, 0.34765625, ...] } ], "status_code": 200 } ] }
Step 5: Configure semantic search
Follow these steps to configure semantic search.
Step 5.1: Create an ingest pipeline
First, create an ingest pipeline that uses the model in Amazon SageMaker to create embeddings from the input text:
PUT /_ingest/pipeline/my_bedrock_embedding_pipeline
{
"description": "text embedding pipeline",
"processors": [
{
"text_embedding": {
"model_id": "your_bedrock_embedding_model_id_created_in_step4",
"field_map": {
"text": "text_knn"
}
}
}
]
}
Step 5.2: Create a vector index
Next, create a vector index for storing the input text and generated embeddings:
PUT my_index
{
"settings": {
"index": {
"knn.space_type": "cosinesimil",
"default_pipeline": "my_bedrock_embedding_pipeline",
"knn": "true"
}
},
"mappings": {
"properties": {
"text_knn": {
"type": "knn_vector",
"dimension": 1536
}
}
}
}
Step 5.3: Ingest data
Ingest a sample document into the index:
POST /my_index/_doc/1000001
{
"text": "hello world."
}
Step 5.4: Search the index
Run a vector search to retrieve documents from the vector index:
POST /my_index/_search
{
"query": {
"neural": {
"text_knn": {
"query_text": "hello",
"model_id": "your_embedding_model_id_created_in_step4",
"k": 100
}
}
},
"size": "1",
"_source": ["text"]
}